

Intro
This post provides an overview of Amazon Bedrock’s key features. We will explain what Amazon Bedrock is, how to access foundation models through its APIs (InvokeModel versus Converse), and the main inference modes (non‑streaming versus streaming).
We’ll get hands-on: start in the Bedrock console—Playground and Model Catalog—to explore and compare models. Then we’ll switch to AWS Lambda to practice core workflows: listing available models and invoking them with both InvokeModel and the Converse API. By the end, you’ll be ready to ship quickly, with confidence, and choose the best foundation model (FM) for your use case.
Who this is for
If you’re new to Amazon Bedrock, this guide quickly takes you from curiosity to deploying your first AI-powered Lambda application. No agents, no RAG, no Knowledge Bases—just the essentials to get something running end-to-end. Every code snippet is ready to deploy with minimal handlers you can use as-is. If you’ve used Bedrock before, consider this a concise refresher to sharpen your workflow.
What you’ll learn
• What Amazon Bedrock is (in plain terms)
• Which IAM roles and policies are required to use Amazon Bedrock (console and APIs)
• How to choose the right model for your requirements
• Different inference types and their use cases
• The differences between Streaming (ConverseStream) and Non-Streaming (Converse) inference modes
• How to list available Foundation Models (FMs) using Lambda (Python)
• How to call a foundation model from AWS Lambda (Python)
• How to invoke a model using the InvokeModel method and Converse method
Prerequisites
To follow along with this guide, ensure you have the following:
• AWS account in a region that supports Amazon Bedrock (e.g., us‑east‑1 or us‑west‑2)
• Bedrock model access enabled for at least one chat model you plan to use (e.g., amazon.nova-micro-v1:0)
• Permission to create and deploy AWS Lambda functions (Python runtime)
• A Lambda execution role with the following permissions:
a) bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream
b) bedrock:ListFoundationModels
c) CloudWatch Logs permissions for Lambda logging (logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents)
• Optional: Ability to update the Lambda role/policy yourself to avoid waiting for an admin
• Optional (VPC): If your Lambda runs in a private subnet, set up PrivateLink endpoints for Bedrock and required services, DNS, security groups, and routing
Lambda - Runtime SDK versions ℹ️
Ensure your environment has boto3 ≥ 1.42.x and botocore ≥ 1.40.x so Bedrock Runtime’s converse and converse_stream are available. On Lambda, check the preinstalled version (e.g., print(boto3.__version__)). If older, ship a Lambda layer or vendor dependencies to include a recent boto3/botocore.
Some AWS services used here might incur minor charges. I suggest reviewing pricing and keeping an eye on your usage.
Recommended IAM policy
The policy below grants permissions to list and invoke models and to write Lambda logs. Note, these permissions are intentionally broad for learning—restrict them before going to production.
IAM policy for the Lambda execution role
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "BedrockModelAccess",
"Effect": "Allow",
"Action": [
"bedrock:ListFoundationModels",
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "*"
},
{
"Sid": "LambdaBasicLogging",
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*"
}
]
}
In production, please remember to:
• Scope Invoke/Converse actions to exact model ARN(s)
• Limit CloudWatch Logs permissions to your function’s log groups
• Grant only the actions your function needs
• Consider KMS encryption, retries/backoff, appropriate timeouts, and concurrency settings
• Use inference profiles and/or provisioned throughput for predictable latency in production
What is Amazon Bedrock?
Amazon Bedrock is a fully managed AWS service for building, testing, and deploying generative AI applications (no GPU management or model hosting required). It provides a unified way to access leading foundation models (FMs) like Anthropic Claude, Amazon Titan, Amazon Nova , Meta Llama, and Mistral through Bedrock Runtime and the Bedrock Converse API.
Key capabilities at a glance:
• Unified APIs: Bedrock Runtime (InvokeModel) for direct model calls, and Converse for chat, multi-turn conversations, streaming, tool use/function calling, and structured outputs
• Model catalog: Discover leading foundation models by region; availability and versions change frequently
• Safety and controls: Guardrails, content filters, PII redaction, jailbreak/unsafe prompt detection; data encrypted in transit and at rest
• Enterprise integration: AWS IAM, VPC endpoints (PrivateLink), Amazon CloudWatch Logs, AWS KMS, and private networking for controlled access
• Production operations: Provisioned throughput, quotas/limits visibility, logging, and metrics for reliability
• Knowledge Bases for RAG and Agents for workflow/tool orchestration
• Model evaluation: compare models on your tasks/datasets and tailor prompts, safety settings, and outputs to your app
• Model fine-tuning: adapt a base model with your data for domain- or task-specific performance
Data Privacy Basics
• Your prompts and outputs are not used to train or improve the foundation models
• Data is encrypted during transmission with TLS and at rest using AWS KMS
(You control access through IAM and can utilize VPC endpoints (PrivateLink) for private connectivity)
• Some features, such as fine-tuning, Knowledge Bases, embeddings, and Guardrails configs, generate artifacts in your account—typically in S3—that you control (Review the service documentation and set retention or KMS policies before enabling these features)
Choosing the Right Model and Inference Type
Choosing the right model and inference type directly affects latency, cost, and scalability, and may be limited by regional availability. It’s vital to understand the differences between foundation models (FMs) and how they work to choose the best option for your use case.
Model Types
The Amazon Bedrock Model Catalog should be your go‑to for discovering foundation models (FMs) by region, with model cards that outline capabilities, limits, and recommended use cases.
What to check on each card:
• ARN for each available model
• Fit for task: chat, summarization, reasoning, coding, embeddings, image/audio, etc
• Modalities: text-only, vision, audio, or multimodal support
• Supported APIs: Converse/ConverseStream vs. InvokeModel/InvokeModelWithResponseStream (some models are Invoke‑only)
• Context window and token limits, JSON/structured output support, tool/function calling
• Streaming support and guardrail compatibility
• Pricing class, quotas, and regional availability
• Versioning and stability (e.g., long‑lived IDs, inference profile availability)
Inference Types
Put simply, inference is the process of running a trained foundation model (FM) to generate an output from your input (e.g., text, JSON, images). In Amazon Bedrock, the inference type describes how model capacity is provisioned and accessed. The diagram below illustrates the inference process.
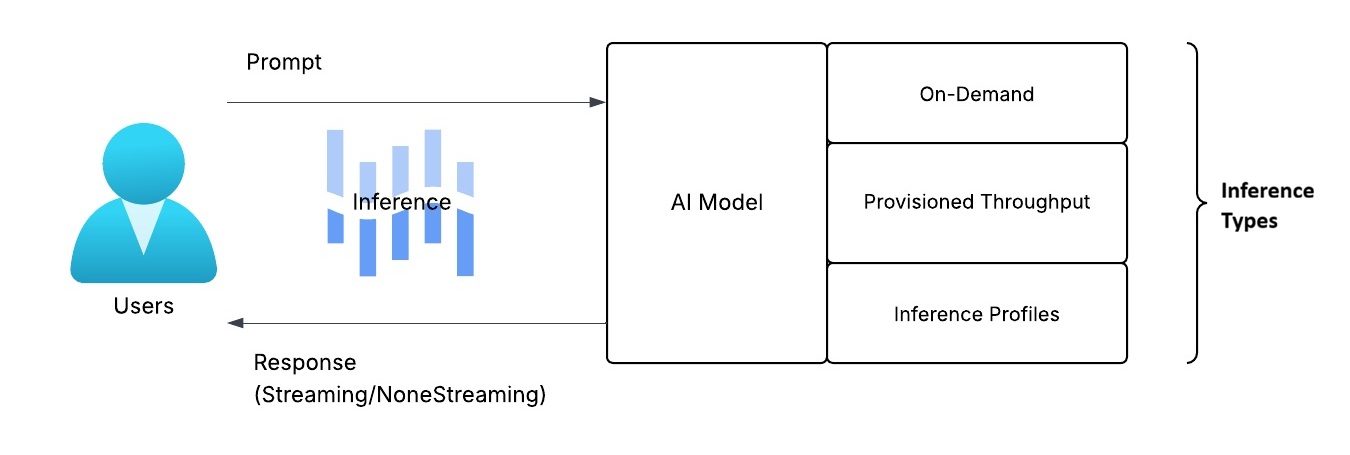
These are three main types:
On-Demand (Serverless, Model ID)
• Invoke directly with a model ID (e.g., amazon.nova-micro-v1:0) via Bedrock Runtime or Converse
• Pay per token; zero capacity setup—ideal for tutorials and low-volume features
• Availability and throttling vary by region and model; check quotas
Provisioned Throughput (Dedicated Capacity)
• Reserve capacity for a specific model; billed hourly
• Offers predictable latency and higher throughput—ideal for production SLOs
• Usually backed by an inference profile; you’ll reference its ARN
Inference Profiles (Stable ARN)
• An addressable ARN you call instead of a model ID
• Can route to on-demand or your provisioned throughput behind the scenes
• Decouples code from model/version changes and simplifies IAM scoping
Streaming vs Non‑Streaming
Once you submit a prompt to an AI model, the response can be delivered to you in two modes: streaming returns tokens as they’re generated, while non‑streaming delivers the full result at once for simpler handling.
Non‑streaming
•Returns the full response when complete; simplest to implement
•Slightly higher perceived latency (user waits for the entire output)
Streaming
• Sends tokens/chunks as they’re generated for faster “time‑to‑first‑byte.”
• Better UX for chat; more code complexity (iterate chunks, flush to client)
Which one to choose?
• Backend jobs, CLI/scripts, short answers, or buffered endpoints (e.g., API Gateway) → Non‑streaming for simplicity and predictable responses
• Interactive chat UIs, assistants, or long/incremental outputs → Streaming for faster first‑token and better UX
Additional Recommendations
• Start on‑demand for trials; move to provisioned throughput when you need consistent latency/scale
• Explore models by region; always review the model card for APIs, limits, pricing, and streaming support
• Build for resilience and cost control: add retries/backoff, monitor tokens/latency in CloudWatch, and set budgets/alerts
ConverseStream vs Converse (Unified Message Format)
Now, that you grasp the basics of inference, the next step is understanding how your app can communicate with Bedrock’s AI models. Bedrock’s Converse APIs offer a consistent request/response format across providers such as Anthropic Claude, Amazon Titan/Nova, Meta Llama, and Mistral. Based on your user experience and performance needs, choose between two modes: Converse for non‑streaming responses and ConverseStream for streaming.
Converse (Non-Streaming):
• Single request → returns the full response when complete
• Simplest to implement; best for short outputs, background tasks, or service‑to‑service calls
• Higher perceived latency because the user waits for the entire response
ConverseStream (Streaming):
• Sends tokens/chunks as they’re generated for faster time‑to‑first‑byte
• Ideal for chat UIs and long responses; supports early stop/cancel patterns
• Slightly more complex: you consume a stream of events and assemble the output
Which one to choose?
Prefer Converse when:
• You send short prompts and expect short answers.
• The caller is another service (not a human) or latency isn’t critical.
Prefer ConverseStream when:
• You’re building a chat UI or long responses.
• You want early stop/cancel and “type‑as‑you‑think” UX.
What requests look like (format)
Both APIs accept:
• Messages: an ordered message history with roles (user, system, assistant) and provider‑agnostic content blocks (e.g., text)
• Optional system instructions to guide behavior
• Inference configuration for generation parameters (e.g., maxTokens, temperature, topP)
• Optional safety or guardrail settings
Common parameters to know
• MaxTokens: upper limit on generated tokens (prevents runaway responses)
• Temperature/topP: balance between creativity and predictability; lower values lead to more focused output
• StopSequences: strings that, if generated, stop the response (useful for delimiting)
InvokeModel (Model’s Native Schema)
A more traditional alternative to Converse is the Bedrock Runtime Invoke APIs. InvokeModel provides a direct, stateless interface to each provider’s native JSON schema—ideal for single‑shot requests or when you need fine‑grained, provider‑specific control. Use InvokeModelWithResponseStream to receive partial output as it’s generated (streaming granularity may vary by model).
How it compares to Converse:
Both are Bedrock Runtime APIs, but Converse normalizes chat‑style requests (messages + optional system instructions), offers unified tool/function calling, and improves portability across providers. Choose Converse for conversational or multi‑message workflows and cross‑model consistency; choose InvokeModel when you need native payloads or features not exposed via Converse.
When to use InvokeModel
• Single‑shot text generation, summarization, translation
• Direct calls to image or multimodal models (where supported)
• You prefer provider‑specific payloads for fine‑grained control
• Stateless interactions (you pass all context you need in each request)
When to use InvokeModelWithResponseStream
• Interactive UIs where time‑to‑first‑byte matters (progressive rendering)
• Long‑form generation where users benefit from seeing output as it’s produced
• Early cancel/stop patterns to save cost and improve UX • Real‑time pipelines that forward chunks to clients (WebSockets, SSE)
• Models/features that are Invoke‑only but still need streaming (provider‑specific schemas)
• Fine‑grained observability over generation (consume and log chunks/events)
You might wonder, “Why can’t I just use Converse (or Invoke) for everything?” The short answer is that Bedrock models differ in capabilities and integrations: some are chat-focused and Converse-enabled, while others are task-specific and Invoke-only (e.g., embeddings, image/audio). Feature availability and streaming modes can vary depending on the provider, model version, and region, and some advanced controls are exclusive to native (Invoke) payloads. A practical rule of thumb: use Converse/ConverseStream for versatile, chat-style workflows with tools and safeguards; use Invoke/InvokeModelWithResponseStream when you need model-native features or the model is Invoke-only.
Not all models support both APIs—some (e.g., embeddings, image/audio) are Invoke‑only; check the model card’s “Supported APIs” for your region
With the foundations set, let’s take a brief tour of Amazon Bedrock and its core building blocks.
Ready to put your knowledge to work? Let’s get started!
Open the Amazon Bedrock console and navigate to Discover → Model Catalog to see which models are available in your AWS Region.
Please note, the model availability changes frequently and varies by Region.
After you select a model, the console links to provider‑specific documentation—parameters, limits, and examples (make sure to explore them).
Next, try the Playgrounds (Test → Chat)
Go to Playgrounds → Chat → pick a model (e.g., Nova Micro or gpt-oss-20b), write a prompt, and click Run.
Add a short system instruction to set tone and boundaries, e.g., “You are a cybersecurity professional.”
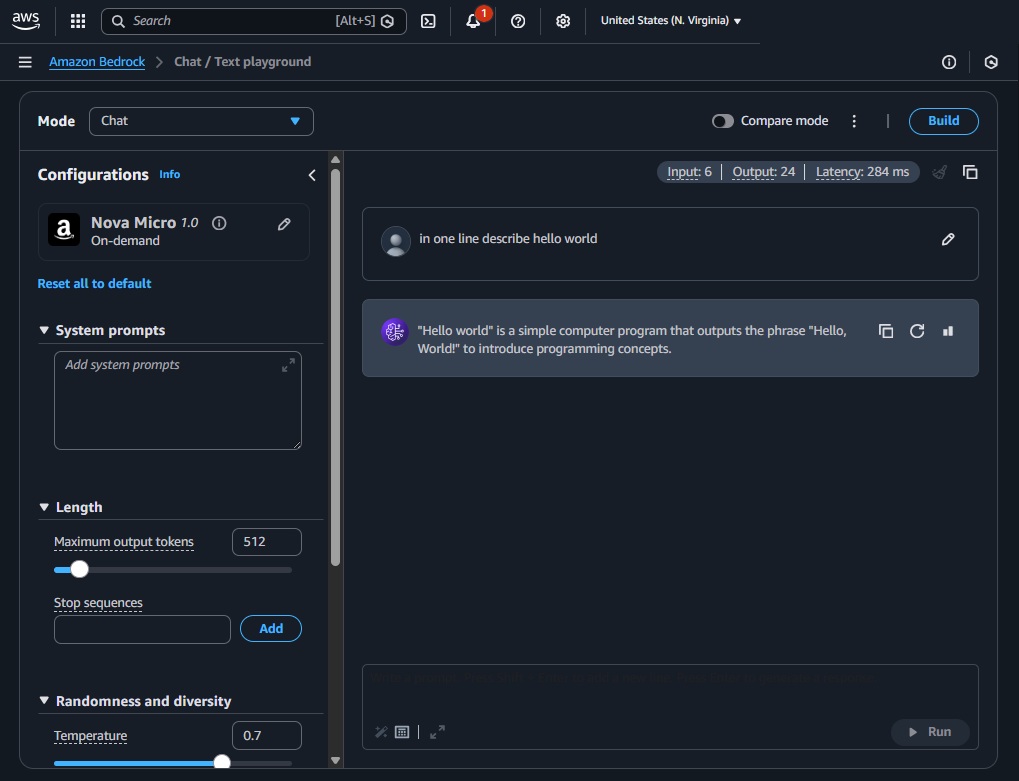
Experiment with parameters and learn by practicing:
• Max tokens (maxTokens): caps output length
• Temperature: lower → more deterministic; higher → more creative
• Top‑p (nucleus): controls sampling diversity; lower → more focused
• Stream toggle: compare streaming vs non‑streamed responses side‑by‑side
• Compare mode: run the same prompt across multiple models
• (Optional) Test Guardrails and Prompt Caching
TIP: Use “View API request” to copy a ready‑made payload/snippet and align your Lambda parameters.
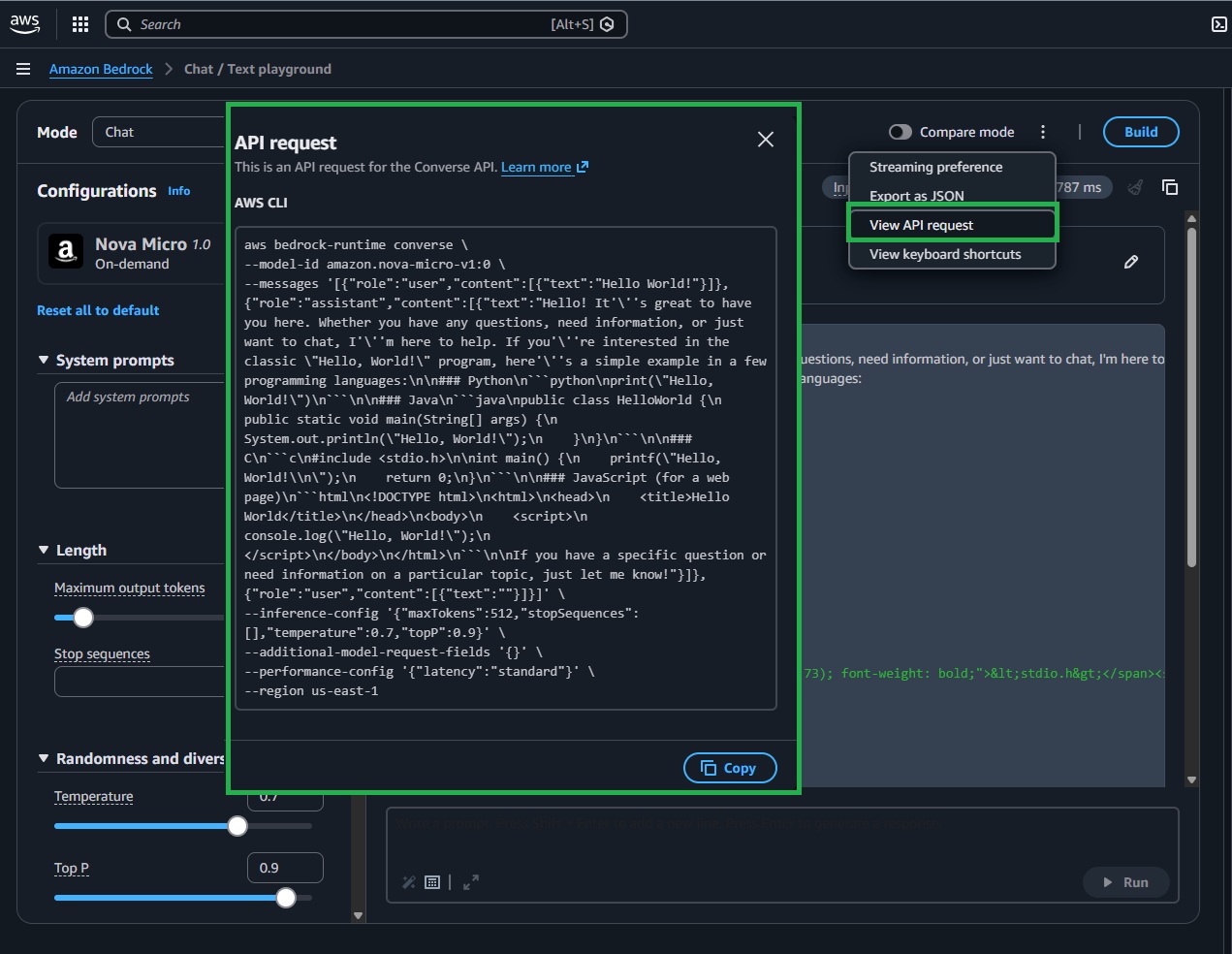
You’ve explored the console and familiarized yourself with AWS AI services. Next, we’ll go over the basics of programmatic interaction with Amazon Bedrock: calling a chat model from your own Lambda function, streaming results, and guiding behavior with a concise system prompt. Master these basics, and you’ll have a solid foundation for GenAI on AWS.
List Available Models Using Lambda Function
Time to jump into Lambda. Begin by listing available models in Amazon Bedrock. Create the function using Python (the sample code was tested using Python 3.13) to match the code samples below. Ensure IAM permissions are set as previously described (e.g., bedrock:ListFoundationModels and CloudWatch Logs). For model invocations, consider increasing the function timeout to around 60 seconds to prevent timeouts; listing models is usually quick.
The snippets below assume us-east-1. Use a Bedrock-supported region where y our chosen model is available and enabled.
Lambda Function Code: list Amazon Bedrock foundation models
import os
import boto3
REGION = os.getenv("AWS_REGION", "us-east-1")
bedrock = boto3.client("bedrock", region_name=REGION)
def lambda_handler(event, context):
"""
Lambda handler that lists foundation models available in the Region.
Returns a simple list of {modelId, providerName}.
"""
resp = bedrock.list_foundation_models()
models = [
{"modelId": m["modelId"], "providerName": m.get("providerName")}
for m in resp.get("modelSummaries", [])
]
return {"models": models}
Make a First Call To a Chat Model
Let’s make our first programmatic call to a chat model. We’ll use Bedrock’s Converse API to prompt the on‑demand Amazon Nova model amazon.nova-micro-v1:0 (docs). Before you run it, ensure model access is enabled in your region and your Lambda role allows bedrock:InvokeModel. I also recommend reviewing the model card in the console to understand capabilities, limits, and pricing. We’ll start with a simple system prompt and a user message, then read back the assistant’s reply.
Lambda Function Code: Basic Invoke
# Use the Conversation API to send a text message to Amazon Nova (Lambda).
# https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-runtime_example_bedrock-runtime_Converse_AmazonNovaText_section.html
# https://docs.aws.amazon.com/pdfs/nova/latest/nova2-userguide/nova2-ug.pdf
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-east-1")
# Set the model ID, e.g., Amazon Nova Micro.
model_id = "amazon.nova-micro-v1:0"
def lambda_handler(event, context):
user_message = "Describe the purpose of a 'hello world' program in one line."
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 256, "temperature": 0.2, "topP": 0.9},
)
# Extract the first text block from the response.
content = response["output"]["message"]["content"]
response_text = next((c["text"] for c in content if "text" in c), "")
# For Lambda, return a response rather than exit/print.
return {
"statusCode": 200,
"body": response_text
}
except (ClientError, Exception) as e:
return {
"statusCode": 500,
"body": f"ERROR: Can't invoke '{model_id}'. Reason: {e}"
}
Have you ran the code? How cool is this?! Let’s expand the script for greater flexibility as you experiment. The version below adds environment variable support (using os) and structured logging for improved configuration and diagnostics. Core parameters—AWS_REGION, MODEL_ID, MAX_TOKENS, TEMPERATURE, TOP_P, LOG_LEVEL—are now controlled by environment variables. Adjust them to see how they influence the model’s responses.
Lambda Function Code: Basic Invoke (v2)
# Use the Converse API to send a text message to Amazon Nova from Lambda.
# Docs: https://docs.aws.amazon.com/bedrock/latest/userguide/bedrock-runtime_example_bedrock-runtime_Converse_AmazonNovaText_section.html
import os, json, logging
import boto3
from botocore.config import Config
from botocore.exceptions import ClientError, BotoCoreError
# Configurable settings via environment variables
REGION = os.getenv("AWS_REGION", "us-east-1")
MODEL_ID = os.getenv("MODEL_ID", "amazon.nova-micro-v1:0")
MAX_TOKENS = int(os.getenv("MAX_TOKENS", "256"))
TEMPERATURE = float(os.getenv("TEMPERATURE", "0.2"))
TOP_P = float(os.getenv("TOP_P", "0.9"))
LOG_LEVEL = os.getenv("LOG_LEVEL", "INFO").upper()
# Basic logger (avoid logging full prompts/responses in production)
log = logging.getLogger()
log.setLevel(LOG_LEVEL)
# Bedrock Runtime client
client = boto3.client(
"bedrock-runtime",
region_name=REGION,
config=Config(retries={"max_attempts": 3, "mode": "standard"}, read_timeout=30),
)
def lambda_handler(event, context):
# Allow overrides from the event payload
prompt = (event or {}).get("prompt", "Describe the purpose of a 'hello world' program in one line.")
system_text = (event or {}).get("system", "You are a helpful assistant.")
model_id = (event or {}).get("modelId", MODEL_ID)
messages = [{"role": "user", "content": [{"text": prompt}]}]
system = [{"text": system_text}]
try:
log.info("Invoking model=%s (region=%s), prompt_len=%d", model_id, REGION, len(prompt))
response = client.converse(
modelId=model_id,
messages=messages,
system=system,
inferenceConfig={"maxTokens": MAX_TOKENS, "temperature": TEMPERATURE, "topP": TOP_P},
)
content = response["output"]["message"]["content"]
response_text = next((c.get("text", "") for c in content if "text" in c), "")
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"reply": response_text}),
}
except (ClientError, BotoCoreError) as e:
log.error("Bedrock invoke failed: %s", e, exc_info=True)
return {
"statusCode": 502,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"error": "Model invocation failed", "detail": str(e)}),
}
except Exception as e:
log.error("Unhandled error: %s", e, exc_info=True)
return {"statusCode": 500, "headers": {"Content-Type": "application/json"}, "body": json.dumps({"error": "Internal error"})}
Try the code with different models: set model_id to another model available in your region. You can find model IDs in the Bedrock Model Catalog or in the output from your previous Lambda run. Then experiment with different prompts in the Lambda event to compare responses.
TIP: in production, avoid logging full prompts and outputs to protect sensitive data.
Next, let’s make a call using the previously discussed InvokeModel. The example below demonstrates a single‑shot, non‑streaming request to Amazon Titan Text Express via Bedrock Runtime. It sends the model’s native JSON payload (inputText and textGenerationConfig), parses the native response, and returns a compact JSON with the original prompt and generated text—ideal for quick tasks that require provider‑specific control.
Lambda Example: InvokeModel (Non‑Streaming)
#https://docs.aws.amazon.com/bedrock/latest/userguide/model-parameters-titan-text.html
import os
import boto3
import json
from botocore.exceptions import ClientError
REGION = os.getenv("AWS_REGION", "us-east-1")
bedrock_runtime = boto3.client("bedrock-runtime", region_name=REGION)
def lambda_handler(event, context):
"""
Lambda handler that invokes the Amazon Titan Text Express model using the `invoke_model` API.
"""
model_id = "amazon.titan-text-express-v1" # Replace with your model ID
prompt = "Describe the purpose of a 'hello world' program in one line."
# Format the request payload using the model's native structure.
native_request = {
"inputText": prompt,
"textGenerationConfig": {
"maxTokenCount": 512,
"temperature": 0.5,
},
}
# Convert the native request to JSON.
request = json.dumps(native_request)
try:
# Invoke the model with the request.
response = bedrock_runtime.invoke_model(modelId=model_id, body=request)
# Decode the response body.
model_response = json.loads(response["body"].read())
# Extract and print the response text.
response_text = model_response["results"][0]["outputText"]
return {
"statusCode": 200,
"body": json.dumps({
"modelId": model_id,
"inputText": prompt,
"outputText": response_text
})
}
except (ClientError, Exception) as e:
return {
"statusCode": 500,
"body": json.dumps({
"error": f"Can't invoke '{model_id}'. Reason: {str(e)}"
})
}
Now it’s your turn—write a function that uses InvokeModelWithResponseStream to stream the output as it’s generated.
Troubleshooting - Quick Hints
- Access Denied: Enable model access in the Bedrock console and make sure IAM allows bedrock:InvokeModel (or bedrock:Converse for the Converse API).
- Model not found: You might be in the wrong region or using a model ID that isn’t enabled.
- Throttling: Use backoff and retries; keep request payloads small during testing.
- Empty results or Access Denied Exception: Verify the region, model access, and IAM permissions.
- Lambda timeouts: Increase the function timeout for streaming or large outputs.
- Outdated boto3/botocore: Ship a Lambda layer with recent versions so the Bedrock runtime and Converse APIs are available.
- Malformed input request: The model might expect a different structure or fields—double-check the model docs and ensure you’re using Converse-compatible parameters.
- On-demand not supported: If a model (e.g., amazon.nova-2-lite-v1:0 in some regions) isn’t available on-demand, use an inference profile, provisioned throughput, or switch to a supported variant (Nova Micro/Sonic) in the same region. Confirm in the Bedrock Catalog and Model access page.
- IAM: Ensure your Lambda role allows bedrock:InvokeModel or bedrock:Converse (optionally scoped to the model ARN) and has CloudWatch Logs permissions.
Were you able to stream using InvokeModelWithResponseStream? If yes—awesome! 🎉 If not, don’t worry: tweak your prompt or parameters, review the model card and docs, try Amazon Q for guidance, or leave a comment below and we’ll troubleshoot together.
Non-Streaming Function VS Streaming Function Using Lambda
Ready for more? Let’s use AWS Lambda to demonstrate the difference between non‑streaming and streaming response modes (the examples below use Converse and ConverseStream).
Non-Streaming Lambda Function
In this example, you’ll create a Lambda function that invokes a model in non‑streaming mode and returns the full response in one go—simple, predictable, and ideal for shorter replies and service‑to‑service workflows. Use the snippet below with your configuration to test.
Lambda Function Code (Non-Streaming example)
# Minimal Lambda handler that calls Bedrock's Converse API (non-streaming).
# Returns the full response once generation is complete.
import os, json, boto3
from botocore.exceptions import ClientError
# Read AWS Region and default model from environment variables.
# Tip: set these in your Lambda configuration.
REGION = os.getenv("AWS_REGION", "us-east-1")
MODEL_ID = os.getenv("MODEL_ID", "amazon.nova-lite-v1:0")
# Create the Bedrock Runtime client (used for both Converse and InvokeModel APIs).
br = boto3.client("bedrock-runtime", region_name=REGION)
def lambda_handler(event, context):
# Read prompt/system overrides from the event payload (if provided).
# This lets you test different inputs without redeploying the function.
prompt = (event or {}).get("prompt", "Describe the purpose of a 'hello world' program in one line.")
system_text = (event or {}).get("system", "You are a helpful assistant.")
try:
# Compose a single-turn conversation: one user message.
messages = [{"role": "user", "content": [{"text": prompt}]}]
# System instructions shape overall behavior across turns (top-level in Converse).
system = [{"text": system_text}]
# Invoke the model and wait for the entire response (non-streaming).
# inferenceConfig controls generation length and creativity.
res = br.converse(
modelId=MODEL_ID,
messages=messages,
system=system,
inferenceConfig={"maxTokens": 512, "temperature": 0.5, "topP": 0.9},
)
# Bedrock returns a unified message format.
# We extract the first text block from the assistant's message content.
content_blocks = res["output"]["message"]["content"]
reply = next((b.get("text", "") for b in content_blocks if "text" in b), "")
# Return a JSON response that plays well with API Gateway/Function URLs.
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"reply": reply}),
}
except (ClientError, Exception) as e:
# Convert errors to an HTTP response (avoid printing sensitive data).
return {
"statusCode": 500,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"error": str(e)}),
}
Streaming Lambda Function
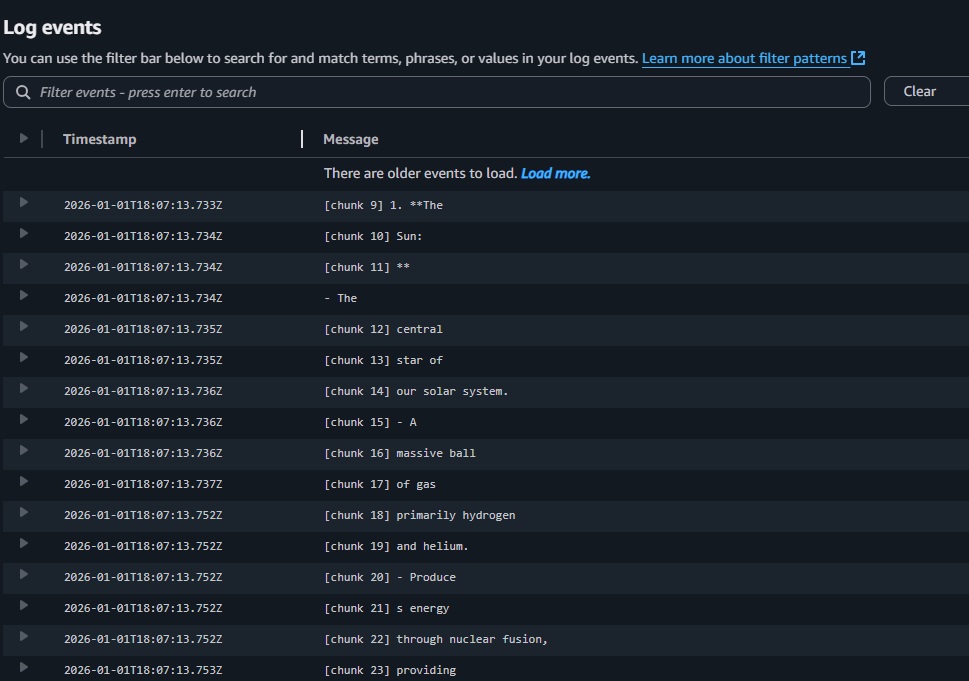
Now let’s switch to streaming. This Lambda uses Bedrock’s ConverseStream to emit tokens as they are generated, logging each chunk to CloudWatch with clear start and end markers and sequence indices for easy debugging. It also records the model’s stopReason and combines all chunks into a single reply for the HTTP response.
TIP: For an actual live user experience, forward chunks to clients (e.g., API Gateway WebSockets) or use Lambda Response Streaming via Function URLs or ALB (not covered in this lab).
You can configure behavior through environment variables (AWS_REGION, MODEL_ID, MAX_TOKENS, TEMPERATURE, TOP_P, READ_TIMEOUT_SEC, LOG_LEVEL). Keep READ_TIMEOUT_SEC below your Lambda timeout to prevent disconnects.
Lambda Function Code (Streaming example)
# lambda_function.py
# Lambda handler that uses Bedrock ConverseStream to stream tokens in real time.
# - Prints each chunk on its own line (with an index) to CloudWatch Logs
# - Shows start/stop markers for clarity
# - Returns the full concatenated reply in the HTTP response
import os
import json
import logging
import boto3
from botocore.config import Config
from botocore.exceptions import ClientError, BotoCoreError
# Config via env vars (set these in Lambda → Configuration → Environment variables)
REGION = os.getenv("AWS_REGION", "us-east-1")
MODEL_ID = os.getenv("MODEL_ID", "amazon.nova-lite-v1:0")
MAX_TOKENS = int(os.getenv("MAX_TOKENS", "512"))
TEMPERATURE = float(os.getenv("TEMPERATURE", "0.5"))
TOP_P = float(os.getenv("TOP_P", "0.9"))
READ_TIMEOUT_SEC = int(os.getenv("READ_TIMEOUT_SEC", "55")) # keep < your Lambda timeout
LOG_LEVEL = os.getenv("LOG_LEVEL", "INFO").upper()
log = logging.getLogger()
log.setLevel(LOG_LEVEL)
# Create Bedrock Runtime client (Nova generations can run longer → increase read_timeout)
br = boto3.client(
"bedrock-runtime",
region_name=REGION,
config=Config(
read_timeout=READ_TIMEOUT_SEC,
retries={"mode": "standard", "max_attempts": 3},
),
)
def lambda_handler(event, context):
"""
Stream a response from Bedrock using ConverseStream.
- Prints each chunk on its own line to CloudWatch Logs for readability
- Returns the full text at the end as JSON
"""
prompt = (event or {}).get("prompt", "Describe the solar system in detail.")
system_text = (event or {}).get("system", "You are a concise, helpful assistant. Refuse unsafe requests.")
# Request payload shared by Converse/ConverseStream
messages = [{"role": "user", "content": [{"text": prompt}]}]
system = [{"text": system_text}]
try:
log.info("Streaming invoke model=%s in %s", MODEL_ID, REGION)
resp = br.converse_stream(
modelId=MODEL_ID,
messages=messages,
system=system,
inferenceConfig={"maxTokens": MAX_TOKENS, "temperature": TEMPERATURE, "topP": TOP_P},
)
# Current response shape ("output.stream"); fall back to older ("stream")
stream_events = resp.get("output", {}).get("stream") or resp.get("stream", [])
chunks = []
stop_reason = None
# Clear visual markers to make logs easier to scan
print("=== Streaming start ===", flush=True)
for idx, evt in enumerate(stream_events, start=1):
# Optional markers when a message/content block starts
if "messageStart" in evt:
print("[event] messageStart", flush=True)
if "contentBlockStart" in evt:
cidx = evt["contentBlockStart"].get("contentBlockIndex")
print(f"[event] contentBlockStart index={cidx}", flush=True)
# Text arrives as deltas; print each on its own line with an index
if "contentBlockDelta" in evt:
delta = evt["contentBlockDelta"]["delta"]
text = delta.get("text")
if text:
chunks.append(text)
print(f"[chunk {idx}] {text}", flush=True)
# Optional markers when a content block/message ends
if "contentBlockStop" in evt:
cidx = evt["contentBlockStop"].get("contentBlockIndex")
print(f"[event] contentBlockStop index={cidx}", flush=True)
if "messageStop" in evt:
stop_reason = evt["messageStop"].get("stopReason")
print(f"[event] messageStop stopReason={stop_reason}", flush=True)
print("=== Streaming end ===", flush=True)
reply = "".join(chunks)
return {
"statusCode": 200,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"reply": reply, "modelId": MODEL_ID, "stopReason": stop_reason}),
}
except (ClientError, BotoCoreError) as e:
log.exception("Model invocation failed")
return {
"statusCode": 502,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"error": "Model invocation failed", "detail": str(e)}),
}
except Exception as e:
log.exception("Unhandled error")
return {
"statusCode": 500,
"headers": {"Content-Type": "application/json"},
"body": json.dumps({"error": "Internal error"}),
}
Summary
Congrats—you’ve just taken your first steps into Amazon Bedrock with AWS Lambda! You now have a solid understanding of how Bedrock works, the different inference styles, and how to choose the right model for your use case. You set up the essential IAM permissions, listed available foundation models from Lambda, and invoked models programmatically—both in non-streaming and streaming modes. You also learned how and when to use the InvokeModel API, providing you with a versatile toolkit for integrating generative AI into real applications.
What you accomplished
• Understood Amazon Bedrock’s role and how it unified access to FMs
• Compared non-streaming and streaming interactions and built Lambda functions for both
• Learned how to list available models and select one suitable for your task
• Invoked models using InvokeModel, including tips for reliable outputs
• Gained familiarity with the IAM permissions needed for secure, least-privilege access
Keep Practicing!
Don’t stop here—momentum is key:
• Experiment with different models and prompts (e.g., Amazon Titan for single-shot tasks, Amazon Nova or chat-optimized models for multi-turn interactions)
• Convert a non-streaming Lambda to streaming and measure latency improvements
• Add guardrails, prompt templates, and observability with CloudWatch to make your app production-ready
• Explore the Converse API when you need context across turns, tools, or multimodal inputs
• Track costs and performance: tune maxTokenCount, temperature, and retries/backoff for stability
If you’re ready for the next step, check out my follow-up post: “Reduce MTTD/MTTR with Amazon Bedrock — From Telemetry to Action”
Have a specific topic you want me to cover next (e.g., “Call a stable Inference Profile ARN,” Guardrails, Prompt Caching, VPC endpoints/PrivateLink, or streaming to API Gateway/AppSync)? Drop a comment below and I’ll prioritize a deep dive.