

Intro
Modern applications face a relentless, evolving threat landscape. Even with AWS WAF guarding your perimeter, your telemetry—WAF logs, application metrics, access logs, CloudTrail events, third‑party signals—quickly becomes a flood. Teams are often stuck in reactive mode: detecting anomalies too late, struggling to find root causes across fragmented systems, and losing precious time before meaningful action is taken.
Generative AI flips that script. By combining AWS WAF, Amazon CloudWatch, and Amazon Bedrock Agents (often referred to as the agent runtime/core), we can transform raw telemetry into actionable insights. In this article, we’ll build a simple web application protected by WAF, stream its metrics and logs to CloudWatch and S3, and feed the signals into Bedrock to:
- Detect anomalies (e.g., spikes in 403s, bot behavior, SQLi patterns)
- Diagnose likely causes using multi‑source context (WAF logs, app metrics, CloudTrail, and external log feeds)
- Decide and act: trigger alerts, open tickets, or automatically mitigate (e.g., update WAF rules, throttle endpoints, invoke Lambda runbooks)
Yes, CloudWatch already provides Generative AI observability for Bedrock workloads—exposing standardized metrics, traces, and logs for model and agent behavior. But walking through a manual, end‑to‑end setup gives you invaluable understanding and control. You’ll learn how to build custom actions, enrich AI context with additional data sources (inside and outside AWS), and design safe automation that’s portable to your custom hybrid and on‑prem environments.
By the end, you’ll have a repeatable pattern that:
- Strengthens your security posture with faster detection and response
- Reduces mean time to diagnose (MTTD) and mean time to resolve (MTTR)
- Monitors the AI itself—token usage, latency, errors, guardrail evaluations—using CloudWatch’s GenAI observability
- Safely automates mitigations with guardrails, RBAC, and auditable workflows
Ready? Let’s build this, step by step
If you are new to Bedrock, I suggest reading my previous post: “From Zero to Amazon Bedrock”
The Concept
We’ll use AWS services with Bedrock as the decision engine. The system will:
• Monitor: Collect WAF traffic, metrics, and logs on a schedule.
• Detect: Prompt Bedrock to flag anomalies.
• Investigate: Pull WAF logs for details and CloudTrail for changes.
• Act: If confident, take action—like emailing admins.
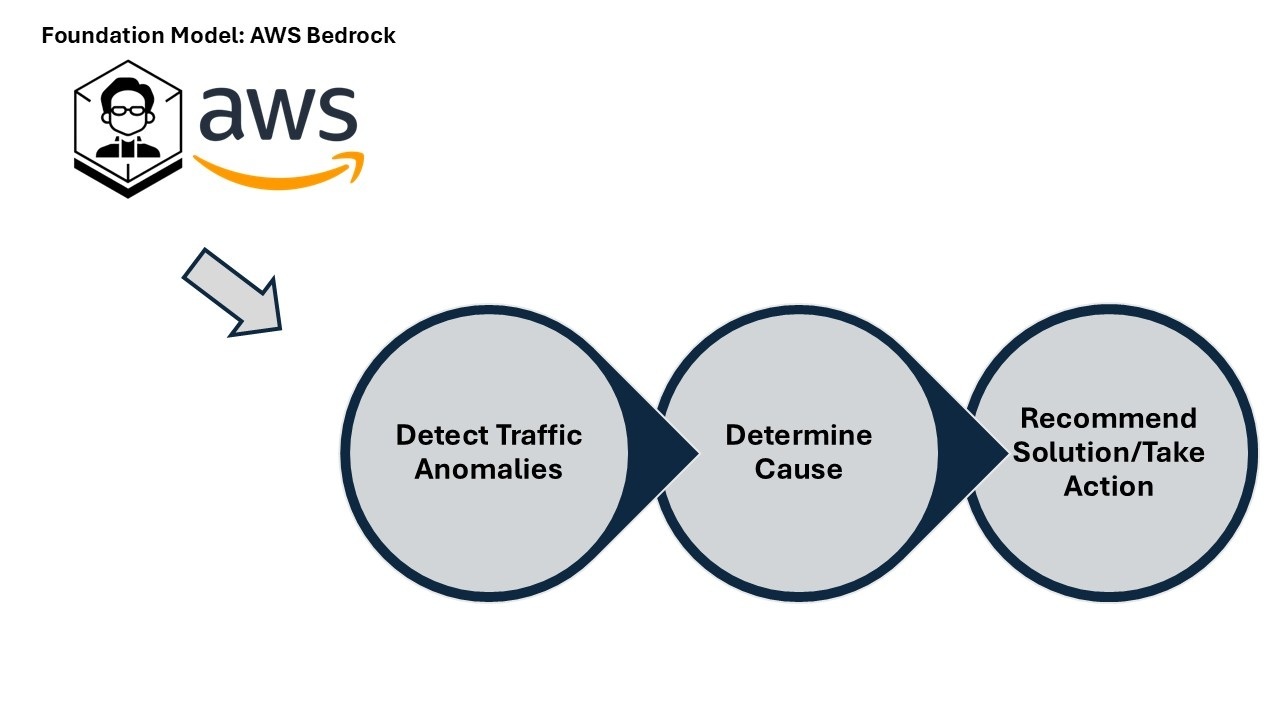
From metrics to action
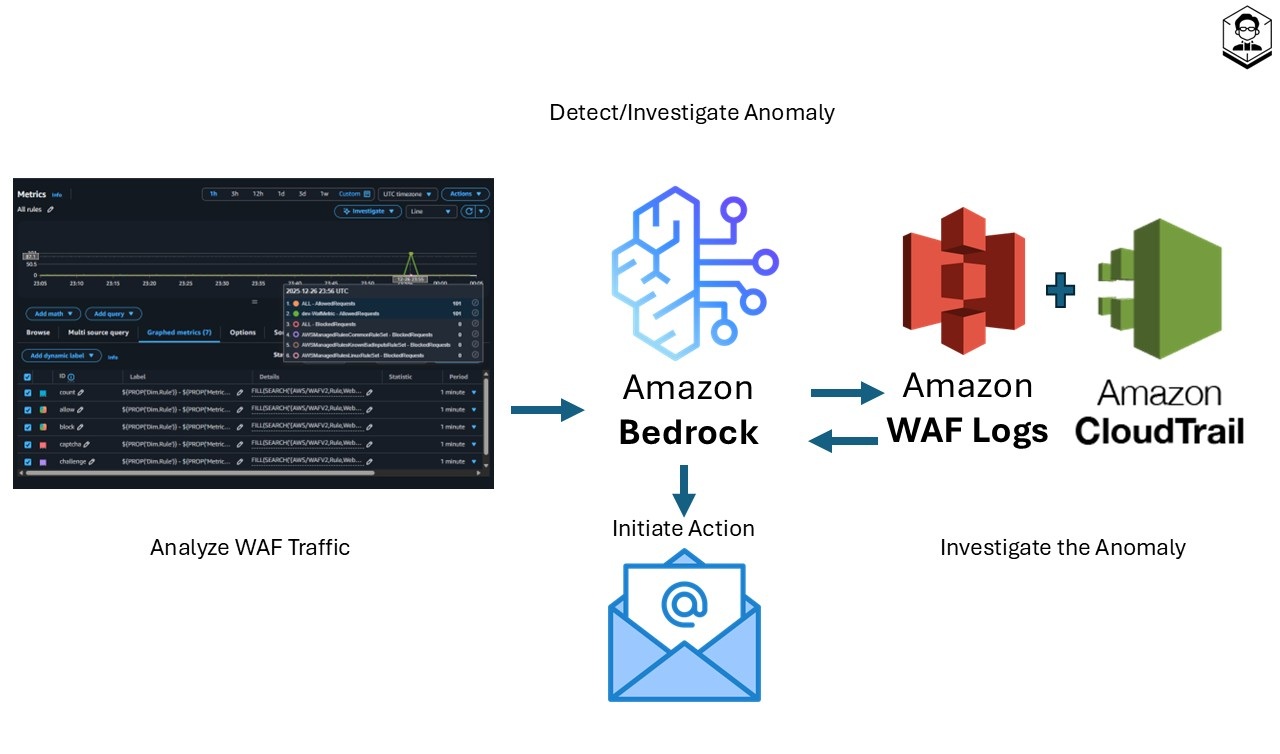
• Analyze metrics: On a fixed schedule, the system reviews AWS WAF CloudWatch metrics to spot unusual patterns.
• Detect anomalies: Signals are sent to Amazon Bedrock, where tailored prompts guide LLM-based anomaly detection.
• Investigate: For flagged events, the system inspects AWS WAF logs (request details) and AWS CloudTrail logs (recent config/permission changes) to determine root cause.
• Take action: Using a confidence score, the system decides next steps—currently, it emails the admin with a detailed summary of the detection and investigation results.
Remember, this is a starter template—meant to spark your creativity. There are thousands of ways to improve and adapt it once you grasp the power of AWS AI services.
This is a playground setup, not meant for production.
The High Level Architectural Diagram
Understanding the architecture
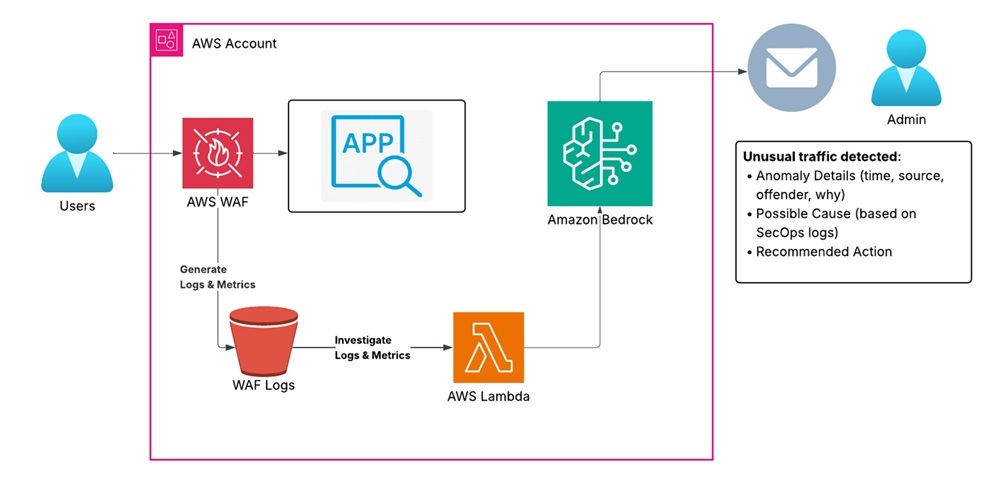
Our application runs in an AWS account with AWS WAF positioned in front to protect it from malicious traffic. AWS WAF publishes traffic metrics to Amazon CloudWatch and produces detailed request logs stored in Amazon S3 (commonly via Amazon Kinesis Data Firehose). Scheduled AWS Lambda functions (triggered by Amazon EventBridge) aggregate these signals and invoke Amazon Bedrock—using tailored prompts—to analyze patterns, detect anomalies, and surface potential threats or misconfigurations. When unusual traffic is detected, the workflow investigates using AWS WAF logs and correlates recent changes from AWS CloudTrail, then emails the application administrator with a summary of the detection and investigation
The App - Architectural Diagram
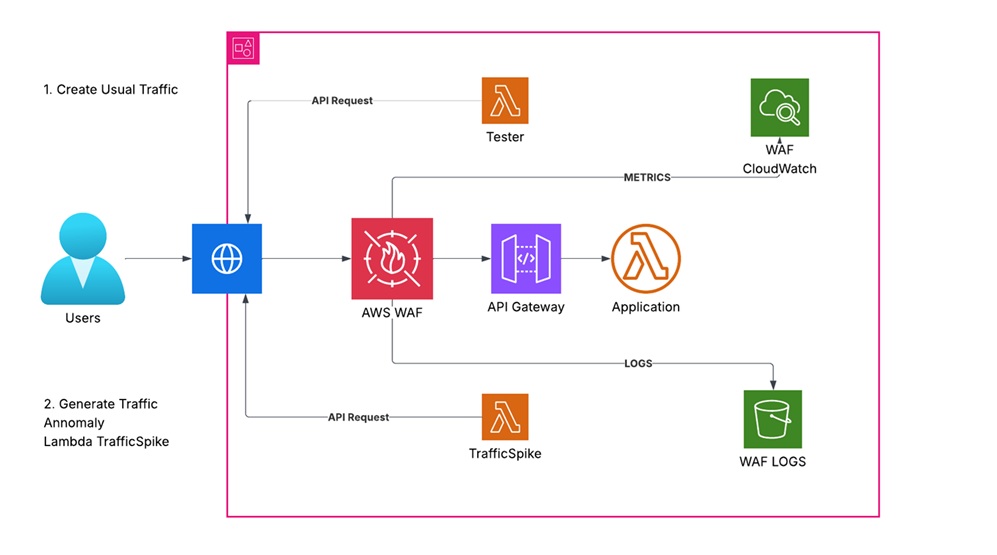
Component breakdown:
Compute:
• AWS Lambda (App function) — simple handler responding to API requests.
• API front door: Amazon API Gateway (REST API) — exposes the Lambda via a public endpoint (API key required via Usage Plan).
Protection:
• AWS WAF (REGIONAL Web ACL) — associated with the API Gateway stage to filter malicious traffic using managed rules.
Observability:
• CloudWatch Logs — Lambda function logs and API Gateway access logs.
• CloudWatch Metrics — Lambda invocations, duration, errors; API Gateway metrics; WAF metrics.
• WAF Logs — delivered via Amazon Kinesis Data Firehose to Amazon S3 for downstream analysis.
Traffic generators:
• Lambda-Tester — generates baseline, benign requests to the API endpoint.
• Lambda-TrafficSpike — simulates bursty or anomalous patterns to test detection.
TIP: Costs and cleanup
Running traffic generators and storing logs may incur charges (API Gateway, Lambda, Firehose, S3, CloudWatch).
To clean up, delete the CloudFormation stack; confirm the S3 bucket is empty or set DeletionPolicy/Retain as appropriate. Consider a lifecycle policy for the WAF logs bucket.
You can deploy the app using the CloudFormation template below, or challenge yourself to build it manually.
If you roll your own, make sure to:
• Associate the WAF Web ACL with the API Gateway stage (REGIONAL).
• Deliver WAF logs to Amazon S3 via Amazon Kinesis Data Firehose.
• Enable API Gateway access logs and Lambda logs in CloudWatch.
• Require an API key via a Usage Plan for calls to the REST API.
• Schedule the TesterLambda with Amazon EventBridge (e.g., rate(5 minutes)).
TIP: How to use this template
• Save the CloudFormation YAML as a file (e.g., app-stack.yaml).
• In your AWS account: CloudFormation → Create stack → With new resources (standard).
• Select “Upload a template file,” then choose your file, set parameters, and create the stack.
CloudFormation Template - The App
AWSTemplateFormatVersion: '2010-09-09'
Description: >
Test CloudFormation Template for a Lambda-based test app.
The app is accessible only via two test Lambdas (Tester and TrafficSpike)
using an API key.
WAF protection is enabled with managed rule groups.
Parameters:
EnvironmentName:
Type: String
Default: "dev"
Description: "Environment name (e.g., dev, prod)"
Resources:
##########################################################
# IAM Role and Policy for AppLambda
##########################################################
AppLambdaRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${EnvironmentName}-AppLambdaRole"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
##########################################################
# AppLambda Function
##########################################################
AppLambda:
Type: AWS::Lambda::Function
DependsOn: [AppLambdaRole]
Properties:
FunctionName: !Sub "${EnvironmentName}-AppLambda"
Handler: index.lambda_handler
Runtime: python3.12
Role: !GetAtt AppLambdaRole.Arn
Code:
ZipFile: |
import json
def lambda_handler(event, context):
return {
"statusCode": 200,
"body": json.dumps({"message": "Hello from the App Lambda!"})
}
Environment:
Variables:
ENV: !Ref EnvironmentName
##########################################################
# IAM Role for TesterLambda
##########################################################
TesterLambdaRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${EnvironmentName}-TesterLambdaRole"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
- arn:aws:iam::aws:policy/AWSXrayWriteOnlyAccess
##########################################################
# TesterLambda Function (scheduled every 5 minutes)
##########################################################
TesterLambda:
Type: AWS::Lambda::Function
DependsOn: [TesterLambdaRole]
Properties:
FunctionName: !Sub "${EnvironmentName}-TesterLambda"
Handler: tester.lambda_handler
Runtime: python3.12
Role: !GetAtt TesterLambdaRole.Arn
Code:
ZipFile: |
import os
import urllib.request
def lambda_handler(event, context):
api_endpoint = os.environ.get("API_ENDPOINT")
api_key = os.environ.get("API_KEY")
req = urllib.request.Request(api_endpoint)
req.add_header("x-api-key", api_key)
try:
with urllib.request.urlopen(req) as response:
body = response.read().decode("utf-8")
print("Response from AppLambda:", body)
except Exception as e:
print("Error invoking API:", e)
return {"status": "success"}
Environment:
Variables:
API_ENDPOINT: !Sub "https://${ApiGatewayRestApi}.execute-api.${AWS::Region}.amazonaws.com/prod/app"
API_KEY: !Ref AppApiKey
##########################################################
# IAM Role for TrafficSpikeLambda
##########################################################
TrafficSpikeLambdaRole:
Type: AWS::IAM::Role
Properties:
RoleName: !Sub "${EnvironmentName}-TrafficSpikeLambdaRole"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Principal:
Service:
- lambda.amazonaws.com
Action:
- sts:AssumeRole
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
##########################################################
# TrafficSpikeLambda Function (simulate traffic spike)
##########################################################
TrafficSpikeLambda:
Type: AWS::Lambda::Function
DependsOn: [TrafficSpikeLambdaRole]
Properties:
FunctionName: !Sub "${EnvironmentName}-TrafficSpikeLambda"
Handler: spike.lambda_handler
Runtime: python3.12
Role: !GetAtt TrafficSpikeLambdaRole.Arn
Code:
ZipFile: |
import os
import urllib.request
def lambda_handler(event, context):
api_endpoint = os.environ.get("API_ENDPOINT")
api_key = os.environ.get("API_KEY")
for i in range(10):
req = urllib.request.Request(api_endpoint)
req.add_header("x-api-key", api_key)
try:
with urllib.request.urlopen(req) as response:
body = response.read().decode("utf-8")
print(f"Call {i+1}: {body}")
except Exception as e:
print(f"Error on call {i+1}:", e)
return {"status": "spike generated"}
Environment:
Variables:
API_ENDPOINT: !Sub "https://${ApiGatewayRestApi}.execute-api.${AWS::Region}.amazonaws.com/prod/app"
API_KEY: !Ref AppApiKey
##########################################################
# API Gateway REST API (fronting AppLambda)
##########################################################
ApiGatewayRestApi:
Type: AWS::ApiGateway::RestApi
Properties:
Name: !Sub "${EnvironmentName}-AppApi"
##########################################################
# API Resource: creates /app path
##########################################################
ApiResource:
Type: AWS::ApiGateway::Resource
DependsOn: [ApiGatewayRestApi]
Properties:
ParentId: !GetAtt ApiGatewayRestApi.RootResourceId
RestApiId: !Ref ApiGatewayRestApi
PathPart: app
##########################################################
# API Method: GET on /app using Lambda Proxy integration
##########################################################
ApiMethod:
Type: AWS::ApiGateway::Method
DependsOn: [ApiResource, AppLambda]
Properties:
RestApiId: !Ref ApiGatewayRestApi
ResourceId: !Ref ApiResource
HttpMethod: GET
AuthorizationType: NONE
ApiKeyRequired: true
Integration:
Type: AWS_PROXY
IntegrationHttpMethod: POST
Uri:
Fn::Join:
- ""
- - "arn:aws:apigateway:"
- !Ref "AWS::Region"
- ":lambda:path/2015-03-31/functions/"
- !GetAtt AppLambda.Arn
- "/invocations"
##########################################################
# API Deployment (without StageName)
##########################################################
ApiDeployment:
Type: AWS::ApiGateway::Deployment
DependsOn: [ApiMethod]
Properties:
RestApiId: !Ref ApiGatewayRestApi
##########################################################
# API Stage: explicitly create "prod" stage
##########################################################
ApiStage:
Type: AWS::ApiGateway::Stage
DependsOn: [ApiDeployment]
Properties:
StageName: prod
DeploymentId: !Ref ApiDeployment
RestApiId: !Ref ApiGatewayRestApi
##########################################################
# API Key and Usage Plan
##########################################################
AppApiKey:
Type: AWS::ApiGateway::ApiKey
DependsOn: [ApiStage]
Properties:
Name: !Sub "${EnvironmentName}-AppApiKey"
Enabled: true
ApiUsagePlan:
Type: AWS::ApiGateway::UsagePlan
DependsOn: [ApiStage]
Properties:
UsagePlanName: !Sub "${EnvironmentName}-UsagePlan"
ApiStages:
- ApiId: !Ref ApiGatewayRestApi
Stage: prod
UsagePlanKey:
Type: AWS::ApiGateway::UsagePlanKey
DependsOn: [ApiUsagePlan, AppApiKey]
Properties:
KeyId: !Ref AppApiKey
KeyType: API_KEY
UsagePlanId: !Ref ApiUsagePlan
##########################################################
# Allow API Gateway to invoke AppLambda
##########################################################
LambdaPermissionForApiGateway:
Type: AWS::Lambda::Permission
DependsOn: [AppLambda]
Properties:
FunctionName: !Ref AppLambda
Action: lambda:InvokeFunction
Principal: apigateway.amazonaws.com
SourceArn: !Sub "arn:aws:execute-api:${AWS::Region}:${AWS::AccountId}:${ApiGatewayRestApi}/*/GET/app"
##########################################################
# WAFv2 Web ACL for API Gateway protection with Managed Rule Groups
##########################################################
WafWebACL:
Type: AWS::WAFv2::WebACL
Properties:
Name: !Sub "${EnvironmentName}-WafWebACL"
Scope: REGIONAL
DefaultAction:
Allow: {}
VisibilityConfig:
CloudWatchMetricsEnabled: true
MetricName: !Sub "${EnvironmentName}-WafMetric"
SampledRequestsEnabled: true
Rules:
- Name: AWSManagedRulesCommonRuleSet
Priority: 1
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesCommonRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesCommonRuleSet
- Name: AWSManagedRulesAdminProtectionRuleSet
Priority: 2
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesAdminProtectionRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesAdminProtectionRuleSet
- Name: AWSManagedRulesKnownBadInputsRuleSet
Priority: 3
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesKnownBadInputsRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesKnownBadInputsRuleSet
- Name: AWSManagedRulesLinuxRuleSet
Priority: 4
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesLinuxRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesLinuxRuleSet
- Name: AWSManagedRulesSQLiRuleSet
Priority: 5
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesSQLiRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesSQLiRuleSet
- Name: AWSManagedRulesUnixRuleSet
Priority: 6
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesUnixRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesUnixRuleSet
- Name: AWSManagedRulesAmazonIpReputationList
Priority: 7
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesAmazonIpReputationList
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesAmazonIpReputationList
- Name: AWSManagedRulesAnonymousIpList
Priority: 8
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesAnonymousIpList
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesAnonymousIpList
- Name: AWSManagedRulesWindowsRuleSet
Priority: 9
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesWindowsRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesWindowsRuleSet
- Name: AWSManagedRulesWordPressRuleSet
Priority: 10
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesWordPressRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesWordPressRuleSet
- Name: AWSManagedRulesPHPRuleSet
Priority: 11
Statement:
ManagedRuleGroupStatement:
VendorName: AWS
Name: AWSManagedRulesPHPRuleSet
OverrideAction:
None: {}
VisibilityConfig:
SampledRequestsEnabled: true
CloudWatchMetricsEnabled: true
MetricName: AWSManagedRulesPHPRuleSet
##########################################################
# Associate the WAF Web ACL with the API Gateway Stage
##########################################################
WafWebACLAssociation:
Type: AWS::WAFv2::WebACLAssociation
DependsOn: [ApiStage, WafWebACL]
Properties:
ResourceArn: !Sub "arn:aws:apigateway:${AWS::Region}::/restapis/${ApiGatewayRestApi}/stages/prod"
WebACLArn: !GetAtt WafWebACL.Arn
##########################################################
# CloudWatch Event Rule to trigger TesterLambda every 5 minutes
##########################################################
TesterLambdaScheduleRule:
Type: AWS::Events::Rule
DependsOn: [TesterLambda]
Properties:
Name: !Sub "${EnvironmentName}-TesterLambdaSchedule"
ScheduleExpression: "rate(5 minutes)"
State: ENABLED
Targets:
- Arn: !GetAtt TesterLambda.Arn
Id: "TesterLambda"
##########################################################
# Permission for CloudWatch Events to invoke TesterLambda
##########################################################
TesterLambdaEventPermission:
Type: AWS::Lambda::Permission
DependsOn: [TesterLambdaScheduleRule]
Properties:
FunctionName: !Ref TesterLambda
Action: lambda:InvokeFunction
Principal: events.amazonaws.com
SourceArn: !GetAtt TesterLambdaScheduleRule.Arn
Outputs:
ApiEndpoint:
Description: "The API Gateway endpoint URL for the app"
Value: !Sub "https://${ApiGatewayRestApi}.execute-api.${AWS::Region}.amazonaws.com/prod/app"
AppApiKey:
Description: "API Key (for test Lambdas)"
Value: !Ref AppApiKey
By now, you should have the app working. Clik on checklist below to validate the setup.
App checklist ✅
• WAF Web ACL and association
AWS Console → WAF → Web ACLs → confirm the ACL exists and Scope is REGIONAL.
Open the ACL → Associations → verify the API Gateway stage “prod” is listed.
• API Gateway (REST API), stage, and API key
AWS Console → API Gateway → APIs → select your API → Stages → confirm “prod.”
AWS Console → API Gateway → API Keys → confirm AppApiKey exists and is attached via a Usage Plan.
Calls without x-api-key should return 403; calls with x-api-key should return 200.
• Lambda functions and environment variables
AWS Console → Lambda → confirm AppLambda, TesterLambda, and TrafficSpikeLambda exist.
For TesterLambda and TrafficSpikeLambda, verify Environmental Variables (API_ENDPOINT, API_KEY) are set to the stack outputs.
• EventBridge schedule (CloudWatch Events)
AWS Console → Amazon EventBridge → Rules → confirm the 5‑minute rule targets TesterLambda and is ENABLED.
Check TesterLambda Invocations in CloudWatch Metrics or recent logs to see periodic calls.
• WAF logging (if enabled)
AWS Console → WAF → Logging and metrics → verify logging is enabled to your Firehose stream and that objects are arriving in Amazon S3.
• CloudWatch logs and metrics
• CloudWatch → Logs → confirm Lambda log groups exist (/aws/lambda/
The Brain - Architectural Diagram
Time for the second core component: the Brain (Amazon Bedrock) 🧠
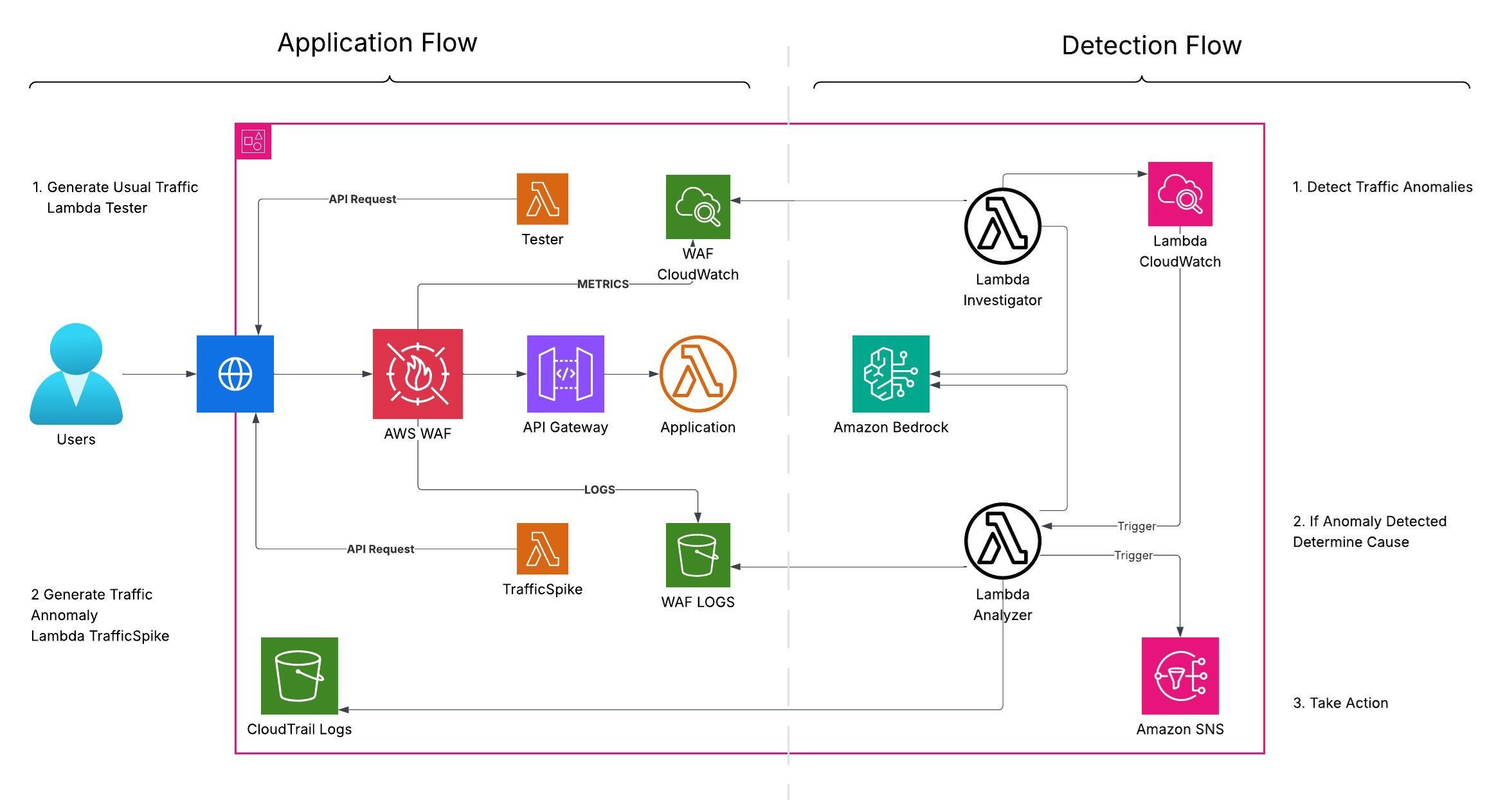
Component breakdown:
Compute
• Lambda Investigator — runs on a schedule (Amazon EventBridge) or manually. It reads AWS WAF metrics from CloudWatch (AWS/WAFV2), detects unusual patterns, and submits a structured prompt to a Bedrock foundation model for anomaly classification and confidence scoring. If confidence exceeds a threshold, it invokes Lambda Analyzer.
• Lambda Analyzer — performs deeper analysis using WAF request logs (Amazon S3), AWS CloudTrail events (recent changes), and WAF configuration (AWS WAFv2). It submits rich context to a Bedrock model, normalizes the output (JSON), and publishes findings to Amazon SNS (email subscription).
Data sources
• Metrics — CloudWatch namespace AWS/WAFV2 (e.g., AllowedRequests, BlockedRequests).
• Logs — WAF request logs in Amazon S3 (via Amazon Kinesis Data Firehose); optionally CloudWatch Logs if you collect app/API logs.
• Changes — AWS CloudTrail LookupEvents for recent configuration or permission changes (e.g., UpdateWebACL, AssociateWebACL, UpdateDistribution on CloudFront).
Orchestration
• Amazon EventBridge — schedules Lambda Investigator (for example, rate(5 minutes)).
• Lambda-to-Lambda — Investigator invokes Analyzer when anomaly confidence exceeds a threshold.
• Optional — Use AWS Step Functions for retries, timeouts, and richer state management.
Amazon Bedrock usage
• Runtime — Bedrock Runtime client; enforce strict JSON with a stop token (optionally enable JSON mode if supported).
• Models — configurable via BEDROCK_MODEL_ID (e.g., amazon.nova-pro-v1:0). Keep the temperature at 0.0 for deterministic output.
• Output normalization — Analyzer parses FM output into strict JSON with robust fallbacks and adds a human-readable email summary.
Prompt engineering tips
• Deterministic outputs: temperature 0, low top_p; JSON-only with a stop token like <END_JSON>.
• Keep context small: baseline, current window, and top‑N IPs/rules/URIs (no raw log dumps).
• Evidence-bound: if data is insufficient, return anomaly=false with a clear reason (don’t guess).
• Enforce schema: validate JSON and retry once with the error message if the output is invalid.
You can deploy the Brain using the function code below, or challenge yourself to build it manually.
Lambda-Investigator
'''
Function Name: Lambda-Investigator
REF: https://blueaisecurity.reduce-mttdmttr-with-amazon-bedrock
Important: This code was generated with AI assistance. Review, test, and secure it before deployment—do not use in production as‑is.
Recommended Timeout: 5 minutes
Recommended Environmental Variables:
- ANALYZER_FUNCTION_NAME - function to send results to
- ANALYZER_REGION - region of the analuzer function
- BEDROCK_MODEL_ID - FM to use
- BEDROCK_REGION - Bedrock's region
- HISTORY_HOURS - how many hours of data should this function analyze
- WAF_ARN - ARN of ACL to analyze data from
Lambda Execusion flow:
Parses inputs/env (window/history/anomaly mode), computes effective history window ⏱
Extracts WAF details from ARN and builds CloudWatch dimensions
Fetches bucketed WAF metrics; fills gaps; retries without Rule=ALL if all zero
Computes baseline stats; finds top anomalies by z-score/percentiles (mode: total/mixed/ratio)
Calls Bedrock (Llama 3 70B) for JSON assessment and normalizes the output
Optionally fires an async alert to an analyzer Lambda; logs if enabled; returns metrics + assessment
'''
import os
import json
import boto3
import logging
from datetime import datetime, timedelta, timezone
from statistics import mean, stdev
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# =========================
# Configurable defaults ✅
# =========================
WINDOW_MINUTES_DEFAULT = 15 # default time window in minutes
HISTORY_DAYS_DEFAULT = 1 # default number of days for baseline/history
# New: Default baseline lookback in hours (preferred over days if provided)
HISTORY_HOURS_DEFAULT = int(os.environ.get("HISTORY_HOURS", "1"))
# Optional bounds (to avoid unreasonable inputs)
WINDOW_MIN_LIMIT = 1
WINDOW_MIN_MAX = 1440 # up to 24 hours
HISTORY_DAYS_MIN = 1
HISTORY_DAYS_MAX = 90 # up to ~3 months
# Bounds for hours (to avoid unreasonable inputs)
HISTORY_HOURS_MIN = 1
HISTORY_HOURS_MAX = 24 * HISTORY_DAYS_MAX # up to same max as days (e.g., 2160 hours if HISTORY_DAYS_MAX=90)
# Analyzer invocation configuration (defaults to your analyzer)
ANALYZER_FUNCTION_NAME_DEFAULT = os.environ.get("ANALYZER_FUNCTION_NAME").strip()
ANALYZER_REGION_DEFAULT = os.environ.get("ANALYZER_REGION").strip()
# Control printing/logging of final investigation result and analyzer message
PRINT_INVESTIGATION_DEFAULT = os.environ.get("PRINT_INVESTIGATION_DEFAULT", "false")
# Only use this Bedrock FM and region
BEDROCK_MODEL_ID = os.environ.get("BEDROCK_MODEL_ID", "meta.llama3-1-70b-instruct-v1:0") #if not provided use llama3
BEDROCK_REGION_DEFAULT = os.environ.get("BEDROCK_REGION", "us-west-2").strip()
# Optional: force analyzer invocation even if no anomaly candidates
ALWAYS_INVOKE_DEFAULT = os.environ.get("ALWAYS_INVOKE", "false")
#Robust string-to-bool converter for env/event inputs; trims and lowercases, supports common truthy/falsy tokens; falls back to default.
#For Normalization
def _to_bool_str(val, default=False):
"""Robust string-to-bool for env and event values."""
if isinstance(val, bool):
return val
if val is None:
return default
s = str(val).strip().lower()
if s in {"1", "true", "t", "yes", "y", "on"}:
return True
if s in {"0", "false", "f", "no", "n", "off"}:
return False
return default
#Safely parse event['body'] into a dict; supports JSON strings or dicts; returns {} when missing or on parse error.
#For Normalization
def _read_json_body(event):
body = event.get("body")
if not body:
return {}
try:
return json.loads(body) if isinstance(body, str) else (body if isinstance(body, dict) else {})
except Exception:
return {}
# Resolves a numeric setting from event/query/body/env with precedence, converts to int, clamps to a safe range, and falls back to the default if invalid
#Parses inputs/env and computes the effective history window.
def _get_int_param(event, key, default, min_v, max_v, env_key=None):
"""
Resolve integer parameter with precedence:
event[key] > queryStringParameters[key] > JSON body[key] > env[env_key] > default.
Applies clamping to [min_v, max_v].
"""
qs = event.get("queryStringParameters") or {}
body = _read_json_body(event)
env_val = os.environ.get(env_key) if env_key else None
candidates = [
event.get(key),
qs.get(key),
body.get(key),
env_val,
default,
]
for val in candidates:
if val is None or val == "":
continue
try:
num = int(val)
num = max(min_v, min(max_v, num))
return num
except Exception:
logger.warning(f"Invalid integer for '{key}': {val} (using next candidate/default)")
continue
return default
#Resolves a text setting with the same precedence, trims/lowercases it, optionally validates against an allowed set, and falls back to the default
#Parses inputs/env and computes the effective history window.
def _get_str_param(event, key, default, env_key=None, allowed=None):
qs = event.get("queryStringParameters") or {}
body = _read_json_body(event)
env_val = os.environ.get(env_key) if env_key else None
candidates = [event.get(key), qs.get(key), body.get(key), env_val, default]
for val in candidates:
if val is None or (isinstance(val, str) and val.strip() == ""):
continue
s = str(val).strip().lower()
if allowed and s not in allowed:
continue
return s
return default
#Resolves a boolean toggle with the same precedence, normalizes common truthy/falsy strings to a Python bool, and falls back to the default
#Parses inputs/env and computes the effective history window.
def _get_bool_param(event, key, default=False, env_key=None):
qs = event.get("queryStringParameters") or {}
body = _read_json_body(event)
env_val = os.environ.get(env_key) if env_key else None
candidates = [event.get(key), qs.get(key), body.get(key), env_val, default]
truthy = {"true", "1", "yes", "y", "on"}
falsy = {"false", "0", "no", "n", "off"}
for val in candidates:
if isinstance(val, bool):
return val
if val is None:
continue
s = str(val).strip().lower()
if s in truthy:
return True
if s in falsy:
return False
return _to_bool_str(default, False)
# Extract WAF details from ARN and set up CloudWatch query
# Parses a WAFv2 ARN to return region, scope ("regional"|"global"), and WebACL name for downstream metric queries.
def _parse_waf_arn(arn: str):
p = arn.split(":")
region = p[3]
seg = p[5].split("/")
return region, seg[0], seg[2] # region, scope (regional/global), webacl name
# Extract WAF details from ARN and set up CloudWatch query
# Builds the CloudWatch dimensions array for WebACL metrics (WebACL, Rule=ALL, Region/Global).
def _dims(scope, webacl, waf_region):
return [
{"Name": "WebACL", "Value": webacl},
{"Name": "Rule", "Value": "ALL"},
{"Name": "Region", "Value": ("Global" if scope == "global" else waf_region)},
]
# Current window and daily aggregates
# Retrieves daily sums for Allowed/Blocked/Counted over the baseline window and computes total and blocked_ratio per day.
def _history_daily(cw, ns, dims, days, end):
# Optional daily aggregates
daily = []
try:
start = end - timedelta(days=days)
for metric in ("AllowedRequests", "BlockedRequests", "CountedRequests"):
r = cw.get_metric_statistics(
Namespace=ns,
MetricName=metric,
Dimensions=dims,
StartTime=start,
EndTime=end,
Period=86400,
Statistics=["Sum"],
)
for dp in r.get("Datapoints", []):
d = dp["Timestamp"].date().isoformat()
rec = next((x for x in daily if x["d"] == d), None)
if not rec:
rec = {"d": d, "allowed": 0, "blocked": 0, "counted": 0}
daily.append(rec)
val = int(dp.get("Sum", 0))
if metric == "AllowedRequests":
rec["allowed"] += val
elif metric == "BlockedRequests":
rec["blocked"] += val
else:
rec["counted"] += val
daily.sort(key=lambda x: x["d"])
for x in daily:
x["total"] = x["allowed"] + x["blocked"] + x["counted"]
x["blocked_ratio"] = round(x["blocked"] / max(x["total"], 1), 4)
except Exception as e:
logger.warning(f"Daily history error: {e}")
return daily
def _align_boundary(dt: datetime, period_secs: int) -> datetime:
# Round down to the nearest period boundary
ts = int(dt.timestamp())
aligned_ts = ts - (ts % period_secs)
return datetime.fromtimestamp(aligned_ts, tz=timezone.utc)
# Fetches bucketed WAF metrics; fills gaps
# Collects CloudWatch WAF metrics into fixed-size buckets over the lookback window, fills missing buckets with zeros, and computes totals and blocked_ratio per bucket.
def _history_series(cw, ns, dims, period_secs, days, end):
"""
Collect fixed-size buckets (e.g., 15-min) across history_days and fill missing buckets with zeros.
Returns: list of {ts, allowed, blocked, counted, total, blocked_ratio}
"""
end_aligned = _align_boundary(end, period_secs)
start = end_aligned - timedelta(days=days)
def fetch_metric(metric_name):
try:
r = cw.get_metric_statistics(
Namespace=ns,
MetricName=metric_name,
Dimensions=dims,
StartTime=start,
EndTime=end_aligned,
Period=period_secs,
Statistics=["Sum"],
)
return r.get("Datapoints", [])
except Exception as e:
logger.warning(f"{metric_name} series fetch error: {e}")
return []
dps_map = {}
for metric in ("AllowedRequests", "BlockedRequests", "CountedRequests"):
for dp in fetch_metric(metric):
ts = _align_boundary(dp["Timestamp"], period_secs)
key = ts.isoformat()
rec = dps_map.get(key) or {"ts": key, "allowed": 0, "blocked": 0, "counted": 0}
val = int(dp.get("Sum", 0))
if metric == "AllowedRequests":
rec["allowed"] += val
elif metric == "BlockedRequests":
rec["blocked"] += val
else:
rec["counted"] += val
dps_map[key] = rec
series = []
cur = start
while cur <= end_aligned:
key = cur.isoformat()
rec = dps_map.get(key, {"ts": key, "allowed": 0, "blocked": 0, "counted": 0})
rec["total"] = rec["allowed"] + rec["blocked"] + rec["counted"]
rec["blocked_ratio"] = round(rec["blocked"] / max(rec["total"], 1), 4)
series.append(rec)
cur = cur + timedelta(seconds=period_secs)
series.sort(key=lambda x: x["ts"])
return series
# Computes baseline stats; finds top anomalies by z-score/percentiles
# Computes a percentile (e.g., p95/p99) with linear interpolation to support anomaly thresholds.
def _percentile(data, p):
if not data:
return 0.0
s = sorted(data)
if len(s) == 1:
return float(s[0])
rank = (len(s) - 1) * (p / 100.0)
low = int(rank)
high = min(low + 1, len(s) - 1)
frac = rank - low
return float(s[low] + (s[high] - s[low]) * (1.0 if high == low else frac))
# Computes baseline stats; finds top anomalies by z-score/percentiles
# Builds baseline averages/std/percentiles and selects top anomaly buckets (total/blocked/ratio) using z-scores and percentile thresholds.
def _compute_series_stats(series, focus="total", nonzero_baseline=True):
allowed = [x.get("allowed", 0) for x in series]
blocked = [x.get("blocked", 0) for x in series]
counted = [x.get("counted", 0) for x in series]
totals = [x.get("total", 0) for x in series]
ratios = [x.get("blocked_ratio", 0.0) for x in series]
nz = [x for x in series if x.get("total", 0) > 0] if nonzero_baseline else series
nz_totals = [x.get("total", 0) for x in nz]
nz_blocked = [x.get("blocked", 0) for x in nz]
nz_ratios = [x.get("blocked_ratio", 0.0) for x in nz]
# Computes baseline stats
# Computes the mean (rounded) of a list with a safe fallback to 0.0.
def avg(a, r=2):
try:
return float(round(mean(a), r)) if a else 0.0
except Exception:
return 0.0
# Computes baseline stats
# Computes the sample standard deviation (rounded) with a safe fallback to 0.0 when insufficient data.
def std(a, r=2):
try:
return float(round(stdev(a), r)) if len(a) >= 2 else 0.0
except Exception:
return 0.0
# Computes baseline stats; supports anomaly thresholds
# Computes a rounded percentile via _percentile with a safe fallback to 0.0.
def pct(a, p, r=2):
try:
return float(round(_percentile(a, p), r)) if a else 0.0
except Exception:
return 0.0
baseline = {
"avg_total": avg(nz_totals),
"std_total": std(nz_totals),
"p95_total": pct(nz_totals, 95),
"p99_total": pct(nz_totals, 99),
"avg_allowed": avg(allowed),
"avg_blocked": avg(blocked),
"avg_counted": avg(counted),
"std_blocked": std(nz_blocked),
"p95_blocked": pct(nz_blocked, 95),
"p99_blocked": pct(nz_blocked, 99),
"avg_blocked_ratio": float(round(mean(nz_ratios), 4)) if nz_ratios else (float(round(mean(ratios), 4)) if ratios else 0.0),
"std_blocked_ratio": float(round(stdev(nz_ratios), 4)) if len(nz_ratios) >= 2 else (float(round(stdev(ratios), 4)) if len(ratios) >= 2 else 0.0),
"p95_blocked_ratio": float(round(_percentile(nz_ratios, 95), 4)) if nz_ratios else (float(round(_percentile(ratios, 95), 4)) if ratios else 0.0),
"p99_blocked_ratio": float(round(_percentile(nz_ratios, 99), 4)) if nz_ratios else (float(round(_percentile(ratios, 99), 4)) if ratios else 0.0),
}
spikes = []
avg_total = baseline["avg_total"]
std_total = baseline["std_total"]
p99_total = baseline["p99_total"]
std_blocked = baseline["std_blocked"]
p99_blocked = baseline["p99_blocked"]
avg_ratio = baseline["avg_blocked_ratio"]
std_ratio = baseline["std_blocked_ratio"]
p95_ratio = baseline["p95_blocked_ratio"]
mult_threshold = max(avg_total * 3 if avg_total > 0 else 0, avg_total + 200)
for x in series:
t = x.get("total", 0)
b = x.get("blocked", 0)
a = x.get("allowed", 0)
c = x.get("counted", 0)
r = x.get("blocked_ratio", 0.0)
candidates = []
if focus in {"total", "mixed"}:
z_total = (t - avg_total) / std_total if std_total > 0 else 0.0
if (std_total > 0 and z_total >= 3.0) or (p99_total and t >= p99_total) or (avg_total > 0 and t >= mult_threshold):
candidates.append(("total_spike", z_total if std_total > 0 else 3.0))
if focus in {"mixed"}:
z_block = (b - baseline["avg_blocked"]) / std_blocked if std_blocked > 0 else 0.0
if (std_blocked > 0 and z_block >= 3.0) or (p99_blocked and b >= p99_blocked):
candidates.append(("blocked_spike", z_block if std_blocked > 0 else 3.0))
if focus in {"mixed", "ratio"}:
z_ratio = (r - avg_ratio) / std_ratio if std_ratio > 0 else 0.0
if (std_ratio > 0 and z_ratio >= 2.0) or (p95_ratio and r >= p95_ratio):
candidates.append(("ratio_spike", z_ratio if std_ratio > 0 else 2.0))
if candidates:
sig_type, sig_score = max(candidates, key=lambda c: c[1])
spikes.append({
"ts": x.get("ts"),
"blocked_ratio": float(round(r, 4)),
"allowed": int(a),
"blocked": int(b),
"counted": int(c),
"total": int(t),
"signal": sig_type,
"z_score": float(round(sig_score, 2)),
})
# Finds top anomalies by z-score/percentiles (ranking)
# Computes a weighted sort key so higher-impact anomaly types come first, then breaks ties by totals, blocked, ratio, and z-score.
def impact_key(s):
weight = {"total_spike": 3, "blocked_spike": 2, "ratio_spike": 1}.get(s["signal"], 0)
return (weight, s["total"], s["blocked"], s["blocked_ratio"], s["z_score"])
spikes.sort(key=impact_key, reverse=True)
spikes = spikes[:5]
return {
"bucket_count": len(series),
"baseline": baseline,
"anomaly_candidates": spikes
}
# Calls Bedrock for JSON assessment and normalizes the output
# Parses FM text into JSON (stripping code-fences and extracting inner JSON) with a safe default fallback on errors.
def _parse_model_json(text: str) -> dict:
t = text.strip()
if t.startswith("```"):
t = t.replace("```json", "").replace("```", "").strip()
try:
return json.loads(t)
except Exception:
s, e = t.find("{"), t.rfind("}")
return json.loads(t[s:e + 1]) if s != -1 and e != -1 and e > s else {
"anomaly_detected": False,
"confidence": 0.5,
"alert_level": "info",
"reason": "Non-JSON FM response.",
"reason_details": {},
"indicators": [],
"recommended_actions": []
}
# Calls Bedrock for JSON assessment and normalizes the output
# Invokes Bedrock (converse API) with the prompt, extracts response text, parses it into JSON, and returns a safe fallback on errors.
def _invoke_bedrock(br, model_id: str, prompt: str, infer_cfg):
"""
Invoke Bedrock meta.llama3-1-70b-instruct-v1:0 and parse JSON.
"""
try:
resp = br.converse(
modelId=model_id,
messages=[{"role": "user", "content": [{"text": prompt}]}],
inferenceConfig=infer_cfg
)
text = "".join(b.get("text", "") for b in resp.get("output", {}).get("message", {}).get("content", []))
ai = _parse_model_json(text)
return ai
except Exception as e:
logger.error(f"Bedrock invocation error: {type(e).__name__}: {e}")
return {
"anomaly_detected": False,
"confidence": 0.4,
"alert_level": "low",
"reason": "Bedrock invocation error.",
"reason_details": {"error": str(e)},
"indicators": [],
"recommended_actions": ["Verify Bedrock permissions/model access/region."]
}
def lambda_handler(event, context):
waf_arn = event.get('waf_arn', os.environ.get('WAF_ARN'))
bedrock_region = event.get('bedrock_region') or BEDROCK_REGION_DEFAULT
# Anomaly mode and baseline behavior
anomaly_mode = _get_str_param(
event,
key="anomaly_mode",
default=os.environ.get("ANOMALY_MODE", "total").strip().lower() if os.environ.get("ANOMALY_MODE") else "total",
env_key="ANOMALY_MODE",
allowed={"total", "mixed", "ratio"}
)
use_nonzero_baseline = _get_bool_param(event, "use_nonzero_baseline", True, env_key="USE_NONZERO_BASELINE")
# Control printing/logging
options = event.get("options") or {}
print_investigation_default = _to_bool_str(PRINT_INVESTIGATION_DEFAULT, False)
print_investigation = options.get("print_investigation")
if print_investigation is None:
print_investigation = print_investigation_default
else:
print_investigation = _to_bool_str(print_investigation, print_investigation_default)
# Optional: always invoke analyzer
always_invoke = _get_bool_param(event, "always_invoke", _to_bool_str(ALWAYS_INVOKE_DEFAULT, False), env_key="ALWAYS_INVOKE")
# Analyzer invocation config (async fire-and-forget)
analyzer_fn_name = event.get("analyzer_function_name") or ANALYZER_FUNCTION_NAME_DEFAULT
analyzer_region = event.get("analyzer_region") or ANALYZER_REGION_DEFAULT
# Get parameters
window_mins = _get_int_param(
event,
key="window_minutes",
default=WINDOW_MINUTES_DEFAULT,
min_v=WINDOW_MIN_LIMIT,
max_v=WINDOW_MIN_MAX,
env_key="WINDOW_MINUTES"
)
history_days = _get_int_param(
event,
key="history_days",
default=HISTORY_DAYS_DEFAULT,
min_v=HISTORY_DAYS_MIN,
max_v=HISTORY_DAYS_MAX,
env_key="HISTORY_DAYS"
)
# Prefer hours over days for baseline lookback
history_hours = _get_int_param(
event,
key="history_hours",
default=HISTORY_HOURS_DEFAULT,
min_v=HISTORY_HOURS_MIN,
max_v=HISTORY_HOURS_MAX,
env_key="HISTORY_HOURS"
)
# Effective baseline window (fractional days supported)
effective_history_days = (history_hours / 24.0) if history_hours else float(history_days)
logger.info(
f"Using window_minutes={window_mins}, history_hours={history_hours} (effective_days={effective_history_days:.4f}), "
f"anomaly_mode={anomaly_mode}, use_nonzero_baseline={use_nonzero_baseline}"
)
waf_ns = os.environ.get("WAF_NAMESPACE", "AWS/WAFV2")
waf_region, scope, webacl = _parse_waf_arn(waf_arn)
end = datetime.now(timezone.utc)
cw = boto3.client("cloudwatch", region_name=waf_region)
dims = _dims(scope, webacl, waf_region)
# Collect full time series at the chosen bucket size (15-min default)
period_secs = window_mins * 60
series = _history_series(cw, waf_ns, dims, period_secs, effective_history_days, end)
# If series is entirely zeros (likely no datapoints), retry without Rule=ALL
if not any((x["allowed"] or x["blocked"] or x["counted"]) for x in series):
dims = [
{"Name": "WebACL", "Value": webacl},
{"Name": "Region", "Value": ("Global" if scope == "global" else waf_region)},
]
series = _history_series(cw, waf_ns, dims, period_secs, effective_history_days, end)
# Current window = last bucket
last = series[-1] if series else {"ts": end.isoformat(), "allowed": 0, "blocked": 0, "counted": 0, "total": 0, "blocked_ratio": 0.0}
# Daily aggregates (optional) — only compute if baseline >= 1 day
if effective_history_days >= 1.0:
daily = _history_daily(cw, waf_ns, dims, int(effective_history_days), end)
else:
daily = []
# Precompute stats for model
series_stats = _compute_series_stats(series, focus=anomaly_mode, nonzero_baseline=use_nonzero_baseline)
metrics = {
"webacl": webacl,
"scope": scope,
"region": waf_region,
"bucket_period_minutes": window_mins,
"history_days": history_days, # keep original for visibility
"history_hours": history_hours, # added for clarity
"effective_history_days": effective_history_days,
"series": series,
"current_window": last,
"daily": daily,
"series_stats": series_stats
}
prompt = (
"You are a security analytics expert. Analyze the AWS WAF time series below (fixed-size buckets across history_hours or days).\n"
"Return ONLY JSON with keys: anomaly_detected(bool), confidence(0-1), alert_level(info|low|medium|high|critical), "
"reason(string), reason_details(object), indicators(string[]), recommended_actions(string[]).\n"
"In reason_details, include concrete numbers: "
"baseline.avg_total, baseline.std_total, baseline.p95_total, baseline.p99_total, current_window.total, "
"baseline.avg_blocked_ratio, baseline.std_blocked_ratio, baseline.p95_blocked_ratio, current_window.blocked_ratio. "
"Reference any top anomalies by timestamp and signal type from series_stats.anomaly_candidates.\n"
"If no anomaly, still populate reason_details explaining stability vs baseline.\n"
f"MetricsSummary:{json.dumps(metrics, separators=(',', ':'))}"
)
# Bedrock: only use meta.llama3-1-70b-instruct-v1:0
br = boto3.client("bedrock-runtime", region_name=bedrock_region)
infer_cfg = {"maxTokens": 512, "temperature": 0.1, "topP": 0.9}
ai = _invoke_bedrock(br, BEDROCK_MODEL_ID, prompt, infer_cfg)
# Normalize output and ensure reason_details present
ai["confidence"] = float(max(0.0, min(1.0, ai.get("confidence", 0.5))))
if ai.get("alert_level") not in {"info", "low", "medium", "high", "critical"}:
ai["alert_level"] = "high" if ai.get("anomaly_detected") else "info"
if "reason_details" not in ai or not isinstance(ai.get("reason_details"), dict):
ai["reason_details"] = {
"baseline": series_stats.get("baseline", {}),
"current_window": {
"ts": last.get("ts"),
"blocked_ratio": last.get("blocked_ratio", 0.0),
"blocked": last.get("blocked", 0),
"total": last.get("total", 0)
},
"anomaly_candidates": series_stats.get("anomaly_candidates", [])
}
result = {"metrics": metrics, "anomaly_assessment": ai, "model_used": BEDROCK_MODEL_ID}
# =========================
# Fire-and-forget: forward anomaly to lambda-analyzer
# =========================
analyzer_invocation = {
"enabled": False,
"function_name": analyzer_fn_name,
"status": "skipped",
"mode": "asynchronous",
"region": None,
"status_code": None,
"api_request_id": None,
"reason": "",
"message_preview": None
}
try:
top_candidates = metrics.get("series_stats", {}).get("anomaly_candidates", [])
top = top_candidates[0] if top_candidates else None
should_invoke = bool(analyzer_fn_name) and (bool(top) or always_invoke)
if should_invoke:
# If no anomaly, use the last completed bucket as the window (e.g., last full 15 min)
if not top:
now_utc = datetime.now(timezone.utc)
end_dt = _align_boundary(now_utc, period_secs) # end of the last completed bucket
start_dt = end_dt - timedelta(seconds=period_secs)
alert = {
"id": f"{webacl}-{start_dt.strftime('%Y%m%dT%H%M%SZ')}-no_anomaly",
"type": "waf_no_anomaly",
"probability": float(ai.get("confidence", 0.5)),
"ai_alert_level": ai.get("alert_level"),
"ai_reason": ai.get("reason"),
"window": {
"start": start_dt.isoformat(),
"end": end_dt.isoformat()
},
"context": {
"webacl": webacl,
"scope": scope,
"region": waf_region,
"bucket_period_minutes": window_mins,
"signal": "none",
"z_score": 0.0,
"total": last.get("total", 0),
"blocked": last.get("blocked", 0),
"blocked_ratio": last.get("blocked_ratio", 0.0)
},
# Important: include waf_arn for analyzer convenience
"waf_arn": os.environ.get("WAF_ARN", waf_arn)
}
else:
start_dt = datetime.fromisoformat(top["ts"])
end_dt = start_dt + timedelta(seconds=period_secs)
alert_type_map = {
"total_spike": "waf_total_spike",
"blocked_spike": "waf_blocked_spike",
"ratio_spike": "waf_ratio_spike"
}
alert_type = alert_type_map.get(top.get("signal"), "waf_anomaly")
alert = {
"id": f"{webacl}-{start_dt.strftime('%Y%m%dT%H%M%SZ')}-{top.get('signal','anomaly')}",
"type": alert_type,
"probability": float(ai.get("confidence", 0.5)),
"ai_alert_level": ai.get("alert_level"),
"ai_reason": ai.get("reason"),
"window": {
"start": start_dt.replace(tzinfo=timezone.utc).isoformat(),
"end": end_dt.replace(tzinfo=timezone.utc).isoformat()
},
"context": {
"webacl": webacl,
"scope": scope,
"region": waf_region,
"bucket_period_minutes": window_mins,
"signal": top.get("signal"),
"z_score": top.get("z_score"),
"total": top.get("total"),
"blocked": top.get("blocked"),
"blocked_ratio": top.get("blocked_ratio")
},
# Important: include waf_arn for analyzer convenience
"waf_arn": os.environ.get("WAF_ARN", waf_arn)
}
analyzer_event = {
"window_minutes": window_mins,
"history_days": history_days, # original field for compatibility
"alert": alert
}
# Log the message that will be sent to the analyzer
logger.info(f"Analyzer invocation message: {json.dumps(analyzer_event)}")
# Pick region for invocation (fallback to WAF or Bedrock region)
invoke_region = analyzer_region or waf_region or bedrock_region
lam = boto3.client("lambda", region_name=invoke_region)
analyzer_invocation["enabled"] = True
analyzer_invocation["status"] = "invoked"
analyzer_invocation["region"] = invoke_region
analyzer_invocation["message_preview"] = {
"id": alert["id"],
"type": alert["type"],
"window": alert["window"],
"context": {
"webacl": webacl,
"region": waf_region,
"signal": alert["context"].get("signal")
}
}
# Asynchronous fire-and-forget
resp = lam.invoke(
FunctionName=analyzer_fn_name,
InvocationType="Event", # async
Payload=json.dumps(analyzer_event).encode("utf-8")
)
analyzer_invocation["status_code"] = resp.get("StatusCode")
analyzer_invocation["api_request_id"] = (resp.get("ResponseMetadata") or {}).get("RequestId")
elif not analyzer_fn_name:
analyzer_invocation["reason"] = "ANALYZER_FUNCTION_NAME not set; skipping."
else:
analyzer_invocation["reason"] = "No anomaly candidates to forward (set ALWAYS_INVOKE=true to force)."
except Exception as e:
analyzer_invocation.update({
"status": "error",
"reason": f"{type(e).__name__}: {e}"
})
logger.warning(f"Analyzer async invocation error: {type(e).__name__}: {e}")
# Attach summary (no downstream analyzer result)
result["analyzer_invocation"] = analyzer_invocation
# Print/log the message and investigation results (if enabled)
if print_investigation:
logger.info(json.dumps({
"investigation_result": result,
"note": "Analyzer invoked asynchronously; no downstream analysis included."
}))
return result
Lambda-Investigator - Execusion flow
• Parses inputs/env (window/history/anomaly mode), computes effective history window
• Extracts WAF details from ARN and builds CloudWatch dimensions
• Fetches bucketed WAF metrics; fills gaps; retries without Rule=ALL if all zero
• Computes baseline stats; finds top anomalies by z-score/percentiles (mode: total/mixed/ratio)
• Calls Bedrock (Llama 3 70B) for JSON assessment and normalizes the output
• Optionally fires an async alert to an analyzer Lambda; logs if enabled; returns metrics + assessment
Lambda-Analyzer
'''
Function Name: Lambda-Analyzer
REF: https://blueaisecurity.reduce-mttdmttr-with-amazon-bedrock
Important: This code was generated with AI assistance. Review, test, and secure it before deployment—do not use in production as‑is.
Recomended Timeout: 15 minutes
Required Environmental Variables:
WAF_LOG_BUCKET - bucket name for WAF logs
Required Environmental Variables (if SNS notifications enabled):
SNS_TOPIC_ARN - ARN of SNS to forward results to
SNS_REGION - region of SNS to forward results to
Recommended Environmental Variables:
WAF_REGION - default WAF region (used when alert context doesn’t include a region for REGIONAL scope)
BEDROCK_REGION - Bedrock’s region
BEDROCK_MODEL_ID - FM to use
BEDROCK_READ_TIMEOUT_SECONDS - Bedrock runtime read timeout (seconds)
BEDROCK_CONNECT_TIMEOUT_SECONDS - Bedrock runtime connect timeout (seconds)
USE_BEDROCK_JSON_MODE - enable JSON-only response mode (true/false)
FM_STOP_TOKEN - stop token appended after JSON (e.g., <END_JSON>)
VERBOSE_LOGS - enable verbose logging (true/false)
WAF_LOG_PREFIX - S3 prefix to narrow object listing
CLOUDTRAIL_REGION - region for CloudTrail lookup
S3_MAX_KEYS - max S3 keys per list page
S3_MAX_OBJECTS - max number of S3 objects to parse
S3_MAX_BYTES - total bytes cap for S3 reads
TOP_IPS_LIMIT - number of top offender IPs
TOP_URIS_PER_IP - number of top URIs per offender
TOP_RULES_LIMIT - number of top WAF rules to list
TOP_URIS_AGG_LIMIT - number of aggregated top URIs
TIME_PAD_MINUTES - minutes to widen search window
WAF_ARN - fallback WebACL ARN if not provided in the alert
Lambda Execusion flow:
• Validates the incoming alert and time window; falls back to a default if missing
• Initializes AWS clients (S3, CloudTrail, WAFv2, Bedrock, SNS) with proper regions/timeouts
• Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
• Looks up CloudTrail events for WAF/CloudFront; filters significant changes; creates concise change summaries
• Fetches WebACL details (via ARN or list+get), including rules and logging configuration
• Builds a payload and invokes Bedrock (Nova Pro) for a strict-JSON assessment; robustly parses/normalizes severity and confidence
• Assembles a structured response (waf_logs, cloudtrail, webacl, analysis_trace, ai_assessment); logs compact and executive summaries
• Optionally formats and publishes a human-readable SNS email if configured
• Returns the full structured analysis result
'''
import os
import json
import gzip
import io
import re
import time
import boto3
import logging
from datetime import datetime, timezone, timedelta
from collections import Counter
from botocore.config import Config
from botocore.exceptions import ParamValidationError, ClientError
# Logger setup (avoid duplicate lines)
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.propagate = False
if not logger.handlers:
ch = logging.StreamHandler()
ch.setLevel(logging.INFO)
logger.addHandler(ch)
# =========================
# Configurable defaults ✅
# =========================
BEDROCK_MODEL_ID = os.environ.get("BEDROCK_MODEL_ID", "amazon.nova-pro-v1:0")
BEDROCK_REGION = os.environ.get("BEDROCK_REGION", "us-west-2")
USE_BEDROCK_JSON_MODE = os.environ.get("USE_BEDROCK_JSON_MODE", "false").strip().lower() in {"true","1","yes","y","on"}
FM_STOP_TOKEN = os.environ.get("FM_STOP_TOKEN", "<END_JSON>")
# Long-running Nova calls (recommend 3600s as per docs)
BEDROCK_READ_TIMEOUT_SECONDS = int(os.environ.get("BEDROCK_READ_TIMEOUT_SECONDS", "3600"))
BEDROCK_CONNECT_TIMEOUT_SECONDS = int(os.environ.get("BEDROCK_CONNECT_TIMEOUT_SECONDS", "10"))
WAF_LOG_BUCKET = os.environ.get("WAF_LOG_BUCKET") # REQUIRED
WAF_LOG_PREFIX = os.environ.get("WAF_LOG_PREFIX", "") # Optional prefix to narrow listing
S3_MAX_KEYS = int(os.environ.get("S3_MAX_KEYS", "500")) # Listing guard
S3_MAX_OBJECTS = int(os.environ.get("S3_MAX_OBJECTS", "200")) # Max objects to parse
S3_MAX_BYTES = int(os.environ.get("S3_MAX_BYTES", str(50 * 1024 * 1024))) # Total bytes cap
CLOUDTRAIL_REGION = os.environ.get("CLOUDTRAIL_REGION", "us-west-2")
WAF_REGION_DEFAULT = os.environ.get("WAF_REGION", "us-west-2")
TOP_IPS_LIMIT = int(os.environ.get("TOP_IPS_LIMIT", "15"))
TOP_URIS_PER_IP = int(os.environ.get("TOP_URIS_PER_IP", "5"))
TOP_RULES_LIMIT = int(os.environ.get("TOP_RULES_LIMIT", "15"))
TOP_URIS_AGG_LIMIT = int(os.environ.get("TOP_URIS_AGG_LIMIT", "20"))
TIME_PAD_MINUTES = int(os.environ.get("TIME_PAD_MINUTES", "5")) # widen search window
VERBOSE_LOGS = os.environ.get("VERBOSE_LOGS", "true").strip().lower() in {"true", "1", "yes", "y", "on"}
# SNS notifications (topic must exist and have email subscription)
SNS_TOPIC_ARN = os.environ.get("SNS_TOPIC_ARN") # REQUIRED
SNS_REGION = os.environ.get("SNS_REGION") # REQUIRED
# =========================
# Helpers
# =========================
# Safely parses a JSON string and returns a fallback if parsing fails.
# Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
def _safe_json_loads(s: str, fallback=None):
try:
return json.loads(s)
except Exception:
return fallback
# Parses ISO-8601 timestamps into UTC datetime objects.
# Validates the incoming alert and time window; falls back to a default if missing
def _parse_iso(dt_str):
try:
return datetime.fromisoformat(str(dt_str).replace("Z", "+00:00")).astimezone(timezone.utc)
except Exception:
return None
# Formats a datetime as an ISO-8601 string in UTC.
# Assembles a structured response (waf_logs, cloudtrail, webacl, analysis_trace, ai_assessment); logs compact and executive summaries
def _fmt_ts(dt: datetime):
if isinstance(dt, datetime):
return dt.replace(tzinfo=timezone.utc).isoformat()
return str(dt)
# Normalizes a WAF scope string to 'REGIONAL' or 'CLOUDFRONT'.
# Initializes AWS clients (S3, CloudTrail, WAFv2, Bedrock, SNS) with proper regions/timeouts
def _waf_scope_from_str(scope_str: str):
s = str(scope_str or "").lower()
if s in ("global", "cloudfront", "cloud-front", "cf"):
return "CLOUDFRONT"
return "REGIONAL"
# Extracts region, scope, name, and ID components from a WAFv2 WebACL ARN.
# Fetches WebACL details (via ARN or list+get), including rules and logging configuration
def _parse_wafv2_arn(arn: str):
"""
arn:aws:wafv2:{region}:{account}:{scope}/webacl/{name}/{id}
scope segment can be 'regional' or 'global' (CloudFront).
"""
try:
parts = arn.split(":")
region = parts[3]
res = parts[5] # e.g. 'regional/webacl/dev-WafWebACL/uuid'
seg = res.split("/")
scope_raw = seg[0].lower() # 'regional' | 'global'
scope = "CLOUDFRONT" if scope_raw in ("global", "cloudfront") else "REGIONAL"
name = seg[2]
webacl_id = seg[3] if len(seg) > 3 else None
return {"region": region, "scope": scope, "name": name, "id": webacl_id}
except Exception:
return None
# =========================
# Robust FM JSON parsing
# =========================
# Robustly parses Bedrock/Nova model output into strict JSON, sanitizing common issues.
# Builds a payload and invokes Bedrock (Nova Pro) for a strict-JSON assessment; robustly parses/normalizes severity and confidence
def _parse_model_json(text: str) -> dict:
# Strip code fences if present
t = text.strip()
t = t.replace("```json", "").replace("```", "").strip()
# If we included a stop token, hard-truncate at it
if FM_STOP_TOKEN and FM_STOP_TOKEN in t:
t = t.split(FM_STOP_TOKEN, 1)[0]
# Try direct JSON parse first
try:
return json.loads(t)
except Exception:
pass
# Fallback: trim to first '{' and last '}'
s, e = t.find("{"), t.rfind("}")
if s != -1 and e != -1 and e > s:
t2 = t[s:e+1]
# Sanitize common issues:
# 1) Remove trailing commas before '}' or ']'
t2 = re.sub(r",\s*([}\]])", r"\1", t2)
# 2) Remove JS-style comments (defensive)
t2 = re.sub(r"//.*?\$", "", t2, flags=re.MULTILINE)
t2 = re.sub(r"/\*.*?\*/", "", t2, flags=re.DOTALL)
t2 = t2.strip()
try:
return json.loads(t2)
except Exception:
if "'" in t2 and '"' not in t2:
t3 = t2.replace("'", '"')
t3 = re.sub(r",\s*([}\]])", r"\1", t3)
try:
return json.loads(t3)
except Exception:
pass
# Final fallback — structured default aligned to contract
return {
"executive_summary": "Model output could not be parsed as strict JSON; returning default.",
"severity": "medium",
"confidence": 0.4,
"anomaly_cause": "Unparseable FM output",
"analysis_sources": [],
"metrics_overview": {},
"primary_offenders": [],
"possible_causes": ["FM returned non-JSON or malformed JSON"],
"methodology": "Attempted to parse FM output using multiple strategies (direct, trimmed braces, sanitized).",
"evidence": {},
"recommended_actions": [
"Enable stop sequence in FM prompt.",
"Reduce temperature to 0.0.",
"Optionally enable Bedrock JSON mode if supported by the model."
]
}
# Publishes a message to an SNS topic with a subject, returning the MessageId on success.
# Optionally formats and publishes a human-readable SNS email if configured
def _publish_sns(sns, topic_arn: str, subject: str, message: str):
"""
Publish a message to SNS with a subject.
Returns the MessageId on success, None on failure.
"""
try:
resp = sns.publish(TopicArn=topic_arn, Subject=subject[:100], Message=message)
mid = resp.get("MessageId")
logger.info(f"[SNS] Published messageId={mid} subject='{subject}'")
return mid
except Exception as e:
logger.warning(f"[SNS] Publish failed: {e}")
return None
# Invokes Bedrock Nova via the Converse API with JSON-mode fallback to obtain the AI assessment.
# Builds a payload and invokes Bedrock (Nova Pro) for a strict-JSON assessment; robustly parses/normalizes severity and confidence
def _invoke_bedrock(br, model_id: str, prompt: str, infer_cfg):
"""
Invoke Amazon Nova via the Converse API. If responseFormat is not supported
by the current SDK/service model, automatically retry without it.
"""
def _build_kwargs(use_json_mode: bool):
prompt_with_stop = (
prompt
+ "\n\nReturn STRICT JSON only. Do NOT include markdown fences."
+ f"\nAppend the token {FM_STOP_TOKEN} immediately after the closing brace of the JSON."
)
k = {
"modelId": model_id,
"messages": [{"role": "user", "content": [{"text": prompt_with_stop}]}],
"inferenceConfig": {
**infer_cfg,
"maxTokens": max(infer_cfg.get("maxTokens", 1536), 4096),
"temperature": 0.0,
"topP": 1.0,
"stopSequences": [FM_STOP_TOKEN],
},
}
# Only add responseFormat if explicitly requested; we will handle validation errors
if use_json_mode:
k["responseFormat"] = {"type": "json"}
return k
try:
# First attempt: use responseFormat if enabled by env
use_json_mode = USE_BEDROCK_JSON_MODE
kwargs = _build_kwargs(use_json_mode)
if VERBOSE_LOGS:
logger.info("[Bedrock/Nova] Invoking model for anomaly analysis...")
try:
resp = br.converse(**kwargs)
except (ParamValidationError, ClientError) as e:
msg = str(e)
# Fallback if responseFormat is not recognized by current SDK/service
if "responseFormat" in msg or "Unknown parameter in input" in msg:
logger.warning("[Bedrock/Nova] 'responseFormat' not supported by current client/service. Retrying without it.")
kwargs = _build_kwargs(False)
resp = br.converse(**kwargs)
else:
raise
# Extract text content
text = "".join(
b.get("text", "")
for b in resp.get("output", {}).get("message", {}).get("content", [])
)
if VERBOSE_LOGS:
logger.info("[Bedrock/Nova] Full raw output: " + (text or "").replace("\n", " "))
parsed = _parse_model_json(text)
if isinstance(parsed, dict):
parsed["_raw_text"] = text
return parsed
except Exception as e:
logger.error(f"Bedrock invocation error: {type(e).__name__}: {e}")
return {
"executive_summary": "Bedrock invocation error.",
"severity": "medium",
"confidence": 0.4,
"anomaly_cause": "Bedrock invocation error",
"error": str(e),
"analysis_sources": ["bedrock"],
"metrics_overview": {},
"primary_offenders": [],
"possible_causes": ["Bedrock permissions/region/model access issue or unsupported parameter"],
"methodology": "Attempted FM inference with JSON mode and fallback, but failed.",
"evidence": {},
"recommended_actions": ["Verify Bedrock permissions and region access; or remove/disable responseFormat; or upgrade boto3/botocore."],
"_raw_text": ""
}
# =========================
# WAF Logs analysis
# =========================
# Detects whether an S3 key indicates gzip-compressed content.
# Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
def _is_gzip_key(key: str):
return key.lower().endswith(".gz") or key.lower().endswith(".gzip")
# Streams JSON records from raw or gzip-compressed bytes.
# Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
def _stream_json_lines(body_bytes: bytes, gzip_encoded: bool):
bio = io.BytesIO(body_bytes)
if gzip_encoded:
try:
with gzip.GzipFile(fileobj=bio, mode="rb") as gz:
data = gz.read()
except Exception:
data = bio.getvalue()
else:
data = bio.getvalue()
for line in data.splitlines():
line = line.strip()
if not line:
continue
rec = _safe_json_loads(line.decode("utf-8", errors="ignore"), None)
if rec is not None:
yield rec
# Lists and reads WAF log objects from S3 within the time window, applying caps and returning records and stats.
# Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
def _collect_waf_logs(s3, bucket, prefix, start_dt: datetime, end_dt: datetime):
t0 = time.time()
if VERBOSE_LOGS:
logger.info(f"[S3/WAF Logs] Listing objects in bucket='{bucket}' prefix='{prefix}' "
f"for window {start_dt.isoformat()} .. {end_dt.isoformat()}")
total_bytes = 0
parsed_objects = 0
records = []
paginator = s3.get_paginator("list_objects_v2")
kwargs = {"Bucket": bucket, "MaxKeys": S3_MAX_KEYS}
if prefix:
kwargs["Prefix"] = prefix
stop = False
pages = 0
for page in paginator.paginate(**kwargs):
pages += 1
for obj in page.get("Contents", []):
if stop:
break
lm = obj.get("LastModified")
key = obj.get("Key")
if not lm or not key:
continue
lm_utc = lm.astimezone(timezone.utc)
if lm_utc < (start_dt - timedelta(minutes=TIME_PAD_MINUTES)) or lm_utc > (end_dt + timedelta(minutes=TIME_PAD_MINUTES)):
continue
if parsed_objects >= S3_MAX_OBJECTS or total_bytes >= S3_MAX_BYTES:
stop = True
break
try:
resp = s3.get_object(Bucket=bucket, Key=key)
body = resp["Body"].read()
total_bytes += len(body)
gzip_encoded = _is_gzip_key(key) or (resp.get("ContentEncoding", "") == "gzip")
for rec in _stream_json_lines(body, gzip_encoded):
ts_ms = rec.get("timestamp")
ts = None
if isinstance(ts_ms, (int, float)):
try:
ts = datetime.fromtimestamp(ts_ms / 1000.0, tz=timezone.utc)
except Exception:
ts = None
elif isinstance(ts_ms, str):
ts = _parse_iso(ts_ms)
ts = ts or lm_utc
if start_dt <= ts <= end_dt:
rec["_ts"] = ts
rec["_source_key"] = key
records.append(rec)
parsed_objects += 1
if VERBOSE_LOGS and parsed_objects % 20 == 0:
logger.info(f"[S3/WAF Logs] Progress: parsed_objects={parsed_objects} total_bytes={total_bytes} records={len(records)}")
except Exception as e:
logger.warning(f"[S3/WAF Logs] Error reading {key}: {e}")
if stop or parsed_objects >= S3_MAX_OBJECTS or total_bytes >= S3_MAX_BYTES:
break
dur = round(time.time() - t0, 2)
if VERBOSE_LOGS:
logger.info(f"[S3/WAF Logs] Completed: records={len(records)} parsed_objects={parsed_objects} "
f"bytes={total_bytes} pages={pages} duration={dur}s")
return records, {"parsed_objects": parsed_objects, "total_bytes": total_bytes, "pages": pages, "duration_sec": dur}
# Summarizes WAF records into top offenders, rules, URIs, and action counts.
# Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
def _summarize_waf_records(records):
offenders = {}
uri_counter = Counter()
rule_counter = Counter()
action_counter = Counter()
for r in records:
http = r.get("httpRequest", {}) or {}
ip = http.get("clientIp") or "unknown"
uri = http.get("uri") or "-"
ua = http.get("httpUserAgent") or "-"
country = http.get("country")
action = (r.get("action") or "").upper() # ALLOW | BLOCK | COUNT
term_rule = r.get("terminatingRuleId") or r.get("terminatingRuleType") or "unknown"
labels = r.get("labels") or []
prof = offenders.get(ip)
if not prof:
prof = {
"ip": ip,
"total": 0, "blocked": 0, "allowed": 0, "counted": 0,
"countries": Counter(),
"user_agents": Counter(),
"uris": Counter(),
"rules": Counter(),
"labels": Counter(),
"samples": []
}
offenders[ip] = prof
prof["total"] += 1
if action == "BLOCK":
prof["blocked"] += 1
elif action == "ALLOW":
prof["allowed"] += 1
elif action == "COUNT":
prof["counted"] += 1
else:
action = "UNKNOWN"
if country:
prof["countries"][country] += 1
if ua:
prof["user_agents"][ua] += 1
if uri:
prof["uris"][uri] += 1
uri_counter[uri] += 1
if term_rule:
prof["rules"][term_rule] += 1
rule_counter[term_rule] += 1
for lab in labels:
if isinstance(lab, dict):
prof["labels"][lab.get("name", "unknown")] += 1
elif isinstance(lab, str):
prof["labels"][lab] += 1
else:
prof["labels"]["unknown"] += 1
if len(prof["samples"]) < 5:
ts = r.get("_ts")
prof["samples"].append(_fmt_ts(ts) if isinstance(ts, datetime) else str(ts))
action_counter[action] += 1
ranked_offenders = sorted(offenders.values(), key=lambda x: (x["blocked"], x["total"]), reverse=True)
top_offenders = []
for o in ranked_offenders[:TOP_IPS_LIMIT]:
top_offenders.append({
"ip": o["ip"],
"total_requests": o["total"],
"blocked_requests": o["blocked"],
"allowed_requests": o["allowed"],
"counted_requests": o["counted"],
"blocked_ratio": round(o["blocked"] / max(o["total"], 1), 4),
"countries_top": o["countries"].most_common(3),
"user_agents_top": o["user_agents"].most_common(3),
"uris_top": o["uris"].most_common(TOP_URIS_PER_IP),
"rules_top": o["rules"].most_common(5),
"labels_top": o["labels"].most_common(5),
"sample_timestamps": o["samples"]
})
top_rules = rule_counter.most_common(TOP_RULES_LIMIT)
top_uris = uri_counter.most_common(TOP_URIS_AGG_LIMIT)
return {
"top_offenders": top_offenders,
"top_rules": top_rules,
"top_uris": top_uris,
"action_summary": dict(action_counter),
"offender_count": len(offenders)
}
# =========================
# CloudTrail analysis
# =========================
# Produces concise human-readable summaries from significant CloudTrail events.
# Looks up CloudTrail events for WAF/CloudFront; filters significant changes; creates concise change summaries
def _summarize_cloudtrail_changes(changes):
summaries = []
for ev in changes:
rp = ev.get("request_parameters") or {}
changed_keys = ", ".join(list(rp.keys())[:6]) if isinstance(rp, dict) else "n/a"
summaries.append({
"event_time": ev.get("event_time"),
"event_name": ev.get("event_name"),
"event_source": ev.get("event_source"),
"username": ev.get("username"),
"source_ip": ev.get("source_ip_address"),
"summary": f"{ev.get('event_name')} by {ev.get('username')} from {ev.get('source_ip_address')} (requestParameters keys: {changed_keys})"
})
return summaries
# Retrieves CloudTrail events for WAF/CloudFront in the time window and filters significant changes.
# Looks up CloudTrail events for WAF/CloudFront; filters significant changes; creates concise change summaries
def _lookup_cloudtrail_changes(ct, start_dt, end_dt):
t0 = time.time()
if VERBOSE_LOGS:
logger.info(f"[CloudTrail] Lookup events in {CLOUDTRAIL_REGION} for window {start_dt.isoformat()} .. {end_dt.isoformat()}")
changes = []
sources = ["wafv2.amazonaws.com", "cloudfront.amazonaws.com"]
def _lookup_with_attrs(attrs):
local_changes = []
try:
paginator = ct.get_paginator("lookup_events")
for page in paginator.paginate(StartTime=start_dt, EndTime=end_dt, LookupAttributes=attrs):
for ev in page.get("Events", []):
ct_json = _safe_json_loads(ev.get("CloudTrailEvent", "{}"), {})
event_time = ev.get("EventTime")
local_changes.append({
"event_time": _fmt_ts(event_time.astimezone(timezone.utc)) if event_time else None,
"event_name": ev.get("EventName"),
"event_source": ev.get("EventSource"),
"username": ev.get("Username"),
"resources": ev.get("Resources"),
"request_parameters": ct_json.get("requestParameters"),
"response_elements": ct_json.get("responseElements"),
"read_only": ct_json.get("readOnly"),
"additional_event_data": ct_json.get("additionalEventData"),
"source_ip_address": ct_json.get("sourceIPAddress"),
"user_agent": ct_json.get("userAgent")
})
return local_changes
except Exception:
next_token = None
while True:
kwargs = {
"StartTime": start_dt,
"EndTime": end_dt,
"LookupAttributes": attrs
}
if next_token:
kwargs["NextToken"] = next_token
try:
resp = ct.lookup_events(**kwargs)
except Exception as e:
logger.warning(f"[CloudTrail] lookup_events error: {e}")
break
for ev in resp.get("Events", []):
ct_json = _safe_json_loads(ev.get("CloudTrailEvent", "{}"), {})
event_time = ev.get("EventTime")
local_changes.append({
"event_time": _fmt_ts(event_time.astimezone(timezone.utc)) if event_time else None,
"event_name": ev.get("EventName"),
"event_source": ev.get("EventSource"),
"username": ev.get("Username"),
"resources": ev.get("Resources"),
"request_parameters": ct_json.get("requestParameters"),
"response_elements": ct_json.get("responseElements"),
"read_only": ct_json.get("readOnly"),
"additional_event_data": ct_json.get("additionalEventData"),
"source_ip_address": ct_json.get("sourceIPAddress"),
"user_agent": ct_json.get("userAgent")
})
next_token = resp.get("NextToken")
if not next_token:
break
return local_changes
for src in sources:
chs = _lookup_with_attrs([{"AttributeKey": "EventSource", "AttributeValue": src}])
changes.extend(chs)
significant = []
for ch in changes:
evn = (ch.get("event_name") or "").lower()
src = (ch.get("event_source") or "").lower()
if any(x in evn for x in [
"updatewebacl", "createwebacl", "deletewebacl",
"associatewebacl", "disassociatewebacl",
"updateipset", "createipset", "deleteipset",
"putloggingconfiguration", "deleteloggingconfiguration",
"updaterule", "createrule", "deleterule",
"putpermissionpolicy", "deletepermissionpolicy"
]):
significant.append(ch)
if src == "cloudfront.amazonaws.com" and ("updatedistribution" in evn or "createdistribution" in evn):
significant.append(ch)
dur = round(time.time() - t0, 2)
if VERBOSE_LOGS:
logger.info(f"[CloudTrail] Completed: events={len(changes)} significant={len(significant)} duration={dur}s")
return changes, significant
# =========================
# WAF WebACL details
# =========================
# Fetches WebACL details (rules and logging) by ARN or by listing and then getting the resource.
# Fetches WebACL details (via ARN or list+get), including rules and logging configuration
def _get_webacl_details(waf, webacl_name: str, scope_str: str, waf_arn: str = None):
"""
Returns: {scope, name, id, arn, rules[], logging}
Prefer fetching by ARN.
"""
scope = _waf_scope_from_str(scope_str)
details = {"scope": scope, "name": webacl_name, "id": None, "arn": None, "rules": [], "logging": None}
parsed = _parse_wafv2_arn(waf_arn) if waf_arn else None
if VERBOSE_LOGS:
logger.info(f"[WAFv2] Fetching WebACL details for name='{webacl_name}' scope='{scope}' arn='{waf_arn}'")
# Try ARN route first
if parsed and parsed.get("name") and parsed.get("id") and parsed.get("scope"):
try:
gw = waf.get_web_acl(Name=parsed["name"], Scope=parsed["scope"], Id=parsed["id"])
web_acl = gw.get("WebACL", {}) or {}
details["name"] = web_acl.get("Name") or parsed["name"]
details["id"] = web_acl.get("Id") or parsed["id"]
details["arn"] = web_acl.get("ARN") or waf_arn
rules = web_acl.get("Rules", []) or []
mod_rules = []
for r in rules:
action = r.get("Action")
mod_rules.append({
"name": r.get("Name"),
"priority": r.get("Priority"),
"action": list(action.keys()) if isinstance(action, dict) else action,
"statement_type": list(r.get("Statement", {}).keys()) if isinstance(r.get("Statement"), dict) else "Unknown",
"visibility_config": r.get("VisibilityConfig", {})
})
details["rules"] = mod_rules
try:
if details.get("arn"):
lg = waf.get_logging_configuration(ResourceArn=details["arn"])
logging_cfg = lg.get("LoggingConfiguration", {}) or {}
details["logging"] = {
"log_destination_configs": logging_cfg.get("LogDestinationConfigs"),
"redacted_fields": logging_cfg.get("RedactedFields")
}
except Exception as e:
logger.info(f"[WAFv2] No logging configuration or restricted access: {e}")
if VERBOSE_LOGS:
logger.info(f"[WAFv2] Completed WebACL fetch: id={details['id']} arn={details['arn']} rules={len(details['rules'])}")
return details
except Exception as e:
logger.warning(f"[WAFv2] get_web_acl by ARN failed, fallback to list: {e}")
# Fallback: list and then get
try:
marker = None
while True:
kwargs = {"Scope": scope}
if marker:
kwargs["NextMarker"] = marker
resp = waf.list_web_acls(**kwargs)
for summary in resp.get("WebACLs", []):
if summary.get("Name") == webacl_name:
details["id"] = summary.get("Id")
details["arn"] = summary.get("ARN")
break
if details["id"] or not resp.get("NextMarker"):
break
marker = resp.get("NextMarker")
if details["id"]:
gw = waf.get_web_acl(Name=webacl_name, Scope=scope, Id=details["id"])
web_acl = gw.get("WebACL", {}) or {}
rules = web_acl.get("Rules", []) or []
mod_rules = []
for r in rules:
action = r.get("Action")
mod_rules.append({
"name": r.get("Name"),
"priority": r.get("Priority"),
"action": list(action.keys()) if isinstance(action, dict) else action,
"statement_type": list(r.get("Statement", {}).keys()) if isinstance(r.get("Statement"), dict) else "Unknown",
"visibility_config": r.get("VisibilityConfig", {})
})
details["rules"] = mod_rules
try:
if details.get("arn"):
lg = waf.get_logging_configuration(ResourceArn=details["arn"])
logging_cfg = lg.get("LoggingConfiguration", {}) or {}
details["logging"] = {
"log_destination_configs": logging_cfg.get("LogDestinationConfigs"),
"redacted_fields": logging_cfg.get("RedactedFields")
}
except Exception as e:
logger.info(f"[WAFv2] No logging configuration or restricted access: {e}")
except Exception as e:
logger.warning(f"[WAFv2] WebACL details error: {e}")
if VERBOSE_LOGS:
logger.info(f"[WAFv2] Completed WebACL fetch: id={details.get('id')} arn={details.get('arn')} rules={len(details.get('rules', []))}")
return details
# =========================
# Human-readable SNS message formatting 📨
# =========================
# Maps severity levels to emoji markers used in human-readable messages.
# Optionally formats and publishes a human-readable SNS email if configured
def _sev_emoji(sev: str) -> str:
s = str(sev or "").lower()
return {
"critical": "🚨",
"high": "⚠️",
"medium": "🟡",
"low": "🟢",
"info": "ℹ️",
}.get(s, "❗")
# Formats (name,count) pairs into compact strings for message sections.
# Optionally formats and publishes a human-readable SNS email if configured
def _fmt_pairs(pairs, limit=5):
try:
return ", ".join([f"{str(k)}({int(v)})" for k, v in (pairs or [])[:limit]])
except Exception:
return "n/a"
# Formats a single offender’s metrics into a concise line for the email body.
# Optionally formats and publishes a human-readable SNS email if configured
def _fmt_offender_line(o: dict) -> str:
ip = o.get("ip")
tot = o.get("total_requests", 0)
blk = o.get("blocked_requests", 0)
ratio = o.get("blocked_ratio", 0.0)
countries = _fmt_pairs(o.get("countries_top"), 3)
rules = _fmt_pairs(o.get("rules_top"), 5)
uris = _fmt_pairs(o.get("uris_top"), 5)
return f"- {ip} — {tot} req (blocked {blk}, ratio {ratio:.2f}); Countries: {countries}; Rules: {rules}; URIs: {uris}"
# Builds the human-readable SNS email body from analysis results and context.
# Optionally formats and publishes a human-readable SNS email if configured
def _format_human_sns_message(alert, start_dt, end_dt, waf_region, webacl_details, waf_summary, ct_summaries, ai_result, analysis_trace):
webacl_name = (alert.get("context", {}) or {}).get("webacl") or webacl_details.get("name") or "WebACL"
scope = (alert.get("context", {}) or {}).get("scope") or webacl_details.get("scope") or "regional"
arn = webacl_details.get("arn") or "n/a"
# Metrics overview (fallback to waf_summary)
mo = ai_result.get("metrics_overview") or {}
totals = waf_summary.get("totals", {})
records_examined = mo.get("records_examined") or waf_summary.get("record_count", 0)
blocked_total = mo.get("blocked_total", totals.get("block", 0))
allowed_total = mo.get("allowed_total", totals.get("allow", 0))
count_total = mo.get("count_total", totals.get("count", 0))
overall_total = mo.get("overall_total", totals.get("total", blocked_total + allowed_total + count_total))
avg_blocked_ratio = mo.get("avg_blocked_ratio_top_offenders", waf_summary.get("avg_blocked_ratio_top_offenders", 0.0))
# Top offenders (limit for email readability)
offenders = (ai_result.get("primary_offenders") or waf_summary.get("top_offenders", []))[:5]
offender_lines = [(_fmt_offender_line(o)) for o in offenders] if offenders else ["- No prominent offenders identified in the window."]
# Top rules/URIs aggregated
top_rules = waf_summary.get("top_rules") or ai_result.get("evidence", {}).get("top_rules") or []
top_uris = waf_summary.get("top_uris") or ai_result.get("evidence", {}).get("top_uris") or []
rules_line = _fmt_pairs(top_rules, 10) if top_rules else "None observed"
uris_line = _fmt_pairs(top_uris, 10) if top_uris else "None observed"
# CloudTrail changes
ct_lines = []
if ct_summaries:
for s in ct_summaries[:10]:
ct_lines.append(f"- {s.get('event_time')} — {s.get('event_name')} — {s.get('summary')}")
else:
ct_lines.append("- No significant CloudTrail changes detected in the window.")
# WebACL quick details
rules_count = len(webacl_details.get("rules", []))
has_logging = bool(webacl_details.get("logging"))
webacl_quick = [
f"- Name: {webacl_name}",
f"- Scope: {scope.upper()}",
f"- Region: {waf_region}",
f"- ARN: {arn}",
f"- Rules: {rules_count} (logging: {'enabled' if has_logging else 'disabled'})",
]
# Recommended actions
recs = ai_result.get("recommended_actions") or ["Review WAF logs and offenders.", "Validate recent configuration changes.", "Consider rate limiting or IP blocking if abuse persists."]
rec_lines = [f"- {r}" for r in recs[:10]]
# Build human message
sev = ai_result.get("severity", "medium")
conf = float(max(0.0, min(1.0, ai_result.get("confidence", 0.5))))
emoji = _sev_emoji(sev)
exec_summary = ai_result.get("executive_summary") or "No executive summary provided."
quick_triage = [
f"- Severity: {sev.upper()} {emoji}",
f"- Confidence: {conf:.2f}",
f"- Total events: {overall_total} (blocked {blocked_total}, allowed {allowed_total}, count {count_total})",
f"- Top offender: {offenders[0].get('ip') if offenders else 'n/a'}",
f"- CloudTrail changes: {len(ct_summaries)}"
]
header = [
f"{emoji} WAF AI Alert: {alert.get('type', 'unknown')} — {sev.upper()}",
f"Alert ID: {alert.get('id', 'n/a')}",
f"Time Window: { _fmt_ts(start_dt) } .. { _fmt_ts(end_dt) }",
f"Model: {BEDROCK_MODEL_ID}",
]
metrics_block = [
f"- Records examined: {records_examined}",
f"- Avg blocked ratio (top offenders): {avg_blocked_ratio:.2f}",
]
lines = []
lines.extend(header)
lines.append("")
lines.append("Executive Summary:")
lines.append(exec_summary)
lines.append("")
lines.append("Quick Triage:")
lines.extend(quick_triage)
lines.append("")
lines.append("Traffic Metrics:")
lines.extend(metrics_block)
lines.append("")
lines.append("Top Offenders:")
lines.extend(offender_lines)
lines.append("")
lines.append("Top Rules:")
lines.append(f"- {rules_line}")
lines.append("")
lines.append("Top URIs:")
lines.append(f"- {uris_line}")
lines.append("")
lines.append("CloudTrail Changes:")
lines.extend(ct_lines)
lines.append("")
lines.append("WebACL Details:")
lines.extend(webacl_quick)
lines.append("")
lines.append("Recommended Actions:")
lines.extend(rec_lines)
lines.append("")
lines.append(f"Analysis duration: {analysis_trace.get('total_duration_sec', 0)}s")
lines.append("")
return "\n".join(lines)
# =========================
# Lambda handler
# =========================
def lambda_handler(event, context):
"""
Expects 'alert' from investigator:
{
"id": "...",
"type": "waf_total_spike|waf_blocked_spike|waf_ratio_spike|waf_no_anomaly",
"window": {"start": ISO, "end": ISO},
"context": {
"webacl": "<name>",
"scope": "regional|global",
"region": "us-west-2",
"bucket_period_minutes": <int>,
"signal": "total_spike|blocked_spike|ratio_spike|none"
},
"waf_arn": "arn:aws:wafv2:..."
}
"""
t_start = time.time()
alert = event.get("alert") or {}
if not alert:
return {"error": "Missing alert from investigator", "event": event}
window = alert.get("window") or {}
start_dt = _parse_iso(window.get("start"))
end_dt = _parse_iso(window.get("end"))
if not (start_dt and end_dt):
end_dt = datetime.now(timezone.utc)
start_dt = end_dt - timedelta(minutes=int(event.get("window_minutes", 15)))
ctx = alert.get("context", {}) or {}
webacl_name = ctx.get("webacl")
scope_str = ctx.get("scope") or "regional"
waf_region = ctx.get("region") or WAF_REGION_DEFAULT
waf_arn = alert.get("waf_arn") or os.environ.get("WAF_ARN")
if VERBOSE_LOGS:
logger.info(f"[Analyzer] Received alert id='{alert.get('id')}' type='{alert.get('type')}' "
f"signal='{ctx.get('signal')}' window={_fmt_ts(start_dt)}..{_fmt_ts(end_dt)}")
# Clients
s3 = boto3.client("s3", region_name=waf_region)
ct = boto3.client("cloudtrail", region_name=CLOUDTRAIL_REGION or waf_region)
waf_client_region = "us-east-1" if _waf_scope_from_str(scope_str) == "CLOUDFRONT" else waf_region
waf = boto3.client("wafv2", region_name=waf_client_region)
br_cfg = Config(
read_timeout=BEDROCK_READ_TIMEOUT_SECONDS,
connect_timeout=BEDROCK_CONNECT_TIMEOUT_SECONDS,
retries={"max_attempts": 3, "mode": "standard"}
)
br = boto3.client("bedrock-runtime", region_name=BEDROCK_REGION, config=br_cfg)
sns_region = SNS_REGION or waf_region
sns = boto3.client("sns", region_name=sns_region) if SNS_TOPIC_ARN else None
start_q = start_dt - timedelta(minutes=TIME_PAD_MINUTES)
end_q = end_dt + timedelta(minutes=TIME_PAD_MINUTES)
# Collect WAF logs
waf_records, s3_stats = _collect_waf_logs(s3, WAF_LOG_BUCKET, WAF_LOG_PREFIX, start_q, end_q)
waf_summary = _summarize_waf_records(waf_records) if waf_records else {
"top_offenders": [],
"top_rules": [],
"top_uris": [],
"action_summary": {},
"offender_count": 0
}
# CloudTrail changes
ct_all, ct_significant = _lookup_cloudtrail_changes(ct, start_q, end_q)
ct_summaries = _summarize_cloudtrail_changes(ct_significant[:25])
# WebACL details
webacl_details = _get_webacl_details(waf, webacl_name, scope_str, waf_arn=waf_arn)
# Analysis trace (durations/counters)
analysis_trace = {
"window_start": _fmt_ts(start_dt),
"window_end": _fmt_ts(end_dt),
"s3_waf_logs": {
"records": len(waf_records),
"parsed_objects": s3_stats.get("parsed_objects", 0),
"total_bytes": s3_stats.get("total_bytes", 0),
"pages": s3_stats.get("pages", 0),
"duration_sec": s3_stats.get("duration_sec", 0)
},
"cloudtrail": {
"events_examined": len(ct_all),
"significant_events": len(ct_significant)
},
"waf_webacl": {
"rules_count": len(webacl_details.get("rules", [])),
"has_logging_config": bool(webacl_details.get("logging"))
},
"total_duration_sec": round(time.time() - t_start, 2)
}
# Build prompt payload
action_summary = waf_summary.get("action_summary", {})
block_count = action_summary.get("BLOCK", 0) or 0
allow_count = action_summary.get("ALLOW", 0) or 0
count_count = action_summary.get("COUNT", 0) or 0
total_events = block_count + allow_count + count_count
avg_blocked_ratio_top = 0.0
if waf_summary.get("top_offenders"):
ratios = [o.get("blocked_ratio", 0.0) for o in waf_summary.get("top_offenders")]
avg_blocked_ratio_top = round(sum(ratios) / max(len(ratios), 1), 4)
prompt_payload = {
"alert": alert,
"window": {"start": _fmt_ts(start_dt), "end": _fmt_ts(end_dt)},
"waf_log_bucket": WAF_LOG_BUCKET,
"s3_stats": s3_stats,
"waf_summary": {
**waf_summary,
"record_count": len(waf_records),
"totals": {
"block": block_count,
"allow": allow_count,
"count": count_count,
"total": total_events
},
"avg_blocked_ratio_top_offenders": avg_blocked_ratio_top
},
"cloudtrail_significant_events": ct_significant[:25],
"cloudtrail_change_summaries": ct_summaries,
"cloudtrail_events_examined": len(ct_all),
"webacl_details": webacl_details,
"analysis_trace": analysis_trace
}
# Expanded FM prompt (descriptive, human-analyst style, executive summary)
prompt = (
"You are a Lead Security Analyst and SRE specializing in WAF Traffic Anomaly Detection.\n\n"
"GOAL: Analyze the provided WAF, CloudTrail, and WebACL context to identify genuine security/operational incidents.\n\n"
"OUTPUT (STRICT JSON ONLY):\n"
"{\n"
' "executive_summary": "Natural language summary suitable for leadership.",\n'
' "severity": "info|low|medium|high|critical",\n'
' "confidence": 0-1,\n'
' "anomaly_cause": "string",\n'
' "analysis_sources": ["waf_logs","cloudtrail","webacl","metrics"],\n'
' "methodology": "Brief description of how you analyzed the data (e.g., examined top offenders, rules, config changes).",\n'
' "metrics_overview": {\n'
' "records_examined": <int>,\n'
' "blocked_total": <int>, "allowed_total": <int>, "count_total": <int>, "overall_total": <int>,\n'
' "avg_blocked_ratio_top_offenders": <float>\n'
" },\n"
' "primary_offenders": [\n'
' {"ip": "string", "blocked_requests": <int>, "total_requests": <int>, "blocked_ratio": <float>, "countries_top": [["US",12]], "rules_top": [["RuleX",10]], "uris_top": [["/path",5]]}\n'
" ],\n"
' "possible_causes": ["string", "..."],\n'
' "evidence": {\n'
' "top_rules": [["RuleName", <count>]],\n'
' "top_uris": [["/path", <count>]],\n'
' "cloudtrail_change_summaries": [{"event_time":"..","event_name":"..","summary":".."}]\n'
" },\n"
' "recommended_actions": ["string", "..."]\n'
"}\n\n"
"Write like a human security professional. Include specifics (IPs, counts, rules). If CloudTrail shows config changes, state what changed. "
"If no changes, say that explicitly. Consider misconfigurations or recent rule updates. "
"Be concise but informative in the executive_summary.\n\n"
f"Data:{json.dumps(prompt_payload, separators=(',', ':'))}"
)
infer_cfg = {"maxTokens": 4096, "temperature": 0.0, "topP": 1.0}
ai_result = _invoke_bedrock(br, BEDROCK_MODEL_ID, prompt, infer_cfg)
# Normalize result
ai_result["confidence"] = float(max(0.0, min(1.0, ai_result.get("confidence", 0.5))))
if ai_result.get("severity") not in {"info", "low", "medium", "high", "critical"}:
any_blocked = (waf_summary.get("action_summary", {}).get("BLOCK", 0) or 0) > 0
ai_result["severity"] = "high" if any_blocked else "medium"
response = {
"analysis_version": datetime.now(timezone.utc).strftime("%Y-%m-%d"),
"model_used": BEDROCK_MODEL_ID,
"input_alert": alert,
"time_window": {"start": _fmt_ts(start_dt), "end": _fmt_ts(end_dt)},
"waf_logs": {
"bucket": WAF_LOG_BUCKET,
"prefix": WAF_LOG_PREFIX,
"records_in_window": len(waf_records),
"parsed_objects": s3_stats.get("parsed_objects", 0),
"total_bytes": s3_stats.get("total_bytes", 0),
"offender_count": waf_summary.get("offender_count"),
"action_summary": waf_summary.get("action_summary"),
"top_offenders": waf_summary.get("top_offenders"),
"top_rules": waf_summary.get("top_rules"),
"top_uris": waf_summary.get("top_uris")
},
"cloudtrail": {
"events_examined": len(ct_all),
"significant_events": ct_significant[:25],
"change_summaries": ct_summaries
},
"webacl": webacl_details,
"analysis_trace": analysis_trace,
"ai_assessment": ai_result
}
# Compact structured summary used for triage/logs
compact_summary = {
"alert_id": alert.get("id"),
"type": alert.get("type"),
"block_count": waf_summary.get("action_summary", {}).get("BLOCK", 0),
"top_offender_ip": (waf_summary.get("top_offenders", [{}])[0].get("ip") if waf_summary.get("top_offenders") else None),
"cloudtrail_changes": len(ct_significant),
"severity": ai_result.get("severity"),
"confidence": ai_result.get("confidence")
}
# Compact structured log for quick triage
try:
logger.info(json.dumps({"summary": compact_summary}))
except Exception:
pass
# Explicitly log the AI executive summary
try:
logger.info("[AI Executive Summary] " + str(ai_result.get("executive_summary", "")))
except Exception:
pass
# Send a human-readable email via SNS 📨
try:
if sns and SNS_TOPIC_ARN:
human_msg = _format_human_sns_message(
alert=alert,
start_dt=start_dt,
end_dt=end_dt,
waf_region=waf_region,
webacl_details=webacl_details,
waf_summary=prompt_payload["waf_summary"],
ct_summaries=ct_summaries,
ai_result=ai_result,
analysis_trace=analysis_trace
)
sev_emoji = _sev_emoji(ai_result.get("severity"))
subject = f"{sev_emoji} WAF AI Alert {alert.get('id')} ({alert.get('type')}) - {ai_result.get('severity','unknown').upper()}"
_publish_sns(sns, SNS_TOPIC_ARN, subject, human_msg)
except Exception as e:
logger.warning(f"[SNS] Failed to send notification: {e}")
# Log the entire Lambda response to CloudWatch (unconditional)
try:
logger.info("[FullResponse] " + json.dumps(response, ensure_ascii=False))
except Exception as e:
logger.warning(f"[FullResponse] Failed to log full response: {e}")
return response
Lambda-Analyzer - Execusion flow
• Validates the incoming alert and time window; falls back to a default if missing
• Initializes AWS clients (S3, CloudTrail, WAFv2, Bedrock, SNS) with proper regions/timeouts
• Collects WAF logs from S3 within a padded window; streams gzip JSON lines; enforces caps; summarizes actions, top offenders, rules, and URIs
• Looks up CloudTrail events for WAF/CloudFront; filters significant changes; creates concise change summaries
• Fetches WebACL details (via ARN or list+get), including rules and logging configuration
• Builds a payload and invokes Bedrock (Nova Pro) for a strict-JSON assessment; robustly parses/normalizes severity and confidence
• Assembles a structured response (waf_logs, cloudtrail, webacl, analysis_trace, ai_assessment); logs compact and executive summaries
• Optionally formats and publishes a human-readable SNS email if configured
• Returns the full structured analysis result
How to set this up ⚙️
Region and model access
Use the same AWS Region as the App.
Ensure Bedrock model access is enabled in that Region for your chosen model(s).
Create two Lambda functions - and upload the code snipets
Lambda Investigator — handles metric collection, baseline comparison, Bedrock evaluation, and confidence gating.
Lambda Analyzer — aggregates logs, configuration, and recent changes for root-cause analysis and reporting, then emails via SNS.
For both functions, increase memory (e.g., ~2048 MB) and set an appropriate timeout (recommended 5 minutes for the investigator, 15 minutes for the analyzer).
Schedule the Investigator
Create an Amazon EventBridge rule (e.g., rate(5 minutes)) targeting Investigator.
Notifications
Create an Amazon SNS topic and subscribe your admin email; confirm the subscription.
IAM permissions (least privilege)
Investigator needs: cloudwatch:GetMetricStatistics (or GetMetricData), bedrock:InvokeModel, lambda:InvokeFunction (to call Analyzer).
Analyzer needs: s3:ListBucket and s3:GetObject for your WAF logs bucket/prefix; wafv2:ListWebACLs, wafv2:GetWebACL, wafv2:GetLoggingConfiguration; cloudtrail:LookupEvents; bedrock:InvokeModel; sns:Publish.
Environment variables (recommended)
- Common: BEDROCK_MODEL_ID, BEDROCK_REGION, USE_BEDROCK_JSON_MODE, FM_STOP_TOKEN (e.g., “
") - Investigator: WEBACL_NAME or WAF_ARN, WAF_REGION, WINDOW_MINUTES (e.g., 15), CONFIDENCE_THRESHOLD (e.g., 0.7), ANALYZER_FUNCTION_NAME.
- Analyzer: WAF_LOG_BUCKET, WAF_LOG_PREFIX (e.g., waf/), S3_MAX_KEYS, S3_MAX_OBJECTS, S3_MAX_BYTES; CLOUDTRAIL_REGION, WAF_REGION; SNS_TOPIC_ARN, SNS_REGION; optional: TOP_IPS_LIMIT, TOP_URIS_PER_IP, TOP_RULES_LIMIT, TOP_URIS_AGG_LIMIT, TIME_PAD_MINUTES, VERBOSE_LOGS.
Bedrock runtime client timeouts
For long-running Nova calls, set runtime config (e.g., BEDROCK_READ_TIMEOUT_SECONDS=3600) and connect_timeout appropriately.
WAF scope and region nuance
For CloudFront (scope CLOUDFRONT), use us-east-1 for WAFv2 API; for REGIONAL, use your Web ACL region.
Validation checklist ✅
• EventBridge → Rules → Investigator schedule is ENABLED and firing on cadence.
• CloudWatch Logs → Investigator and Analyzer log groups exist and show recent runs.
• Bedrock → Model access enabled; Analyzer logs show successful inferences (and JSON parsed without fallback).
• S3 → WAF logs arriving at the expected prefix; Analyzer reads objects within the window.
• WAFv2 → Web ACL details fetch succeeds; logging configuration (Firehose → S3) is visible.
• CloudTrail → LookupEvents returns recent WAF/CloudFront changes; significant events summarized.
• SNS → Email subscription confirmed; alerts arrive with severity, confidence, offenders, rules, URIs, and change summaries.
TIP: Costs and guardrails
• Bedrock inference, Lambda, EventBridge, CloudWatch, CloudTrail, SNS, and S3/Firehose incur charges.
• Use S3 lifecycle policies on WAF logs (e.g., 30–90 days).
• Cap S3 listing and bytes (S3_MAX_KEYS, S3_MAX_OBJECTS, S3_MAX_BYTES) to control analyzer cost/latency.
• Keep Bedrock temperature at 0.0; enforce JSON with a stop token (and optionally JSON mode).
• Consider Step Functions for retries and backoff under noisy traffic conditions.
⚠️ Read Before Testing ⚠️
Lambda Analyzer and Investigator functions are designed for operational troubleshooting and may emit sensitive identifiers at runtime:
• WebACL metadata (name, scope, region) in metrics.
• waf_arn (includes AWS account ID) and WebACL name in logs and forwarded events.
• Full investigation output when PRINT_INVESTIGATION_DEFAULT=true.
If you require strict controls, disable verbose logging and modify the code to sanitize or remove identifiers from logs and responses prior to testing. Validate logging behavior in a non-production environment and ensure access to logs is appropriately restricted.
Time for the test!
Test 1: Regular Traffic ℹ️
For this test, avoid creating unusual traffic. Use the Lambda tester function to simulate a steady load—such as sending one request every 5 minutes. Below is an example of the expected result:
Result: Lambda-Investigator correctly found no anomalies and did not trigger Lambda-Analyzer.
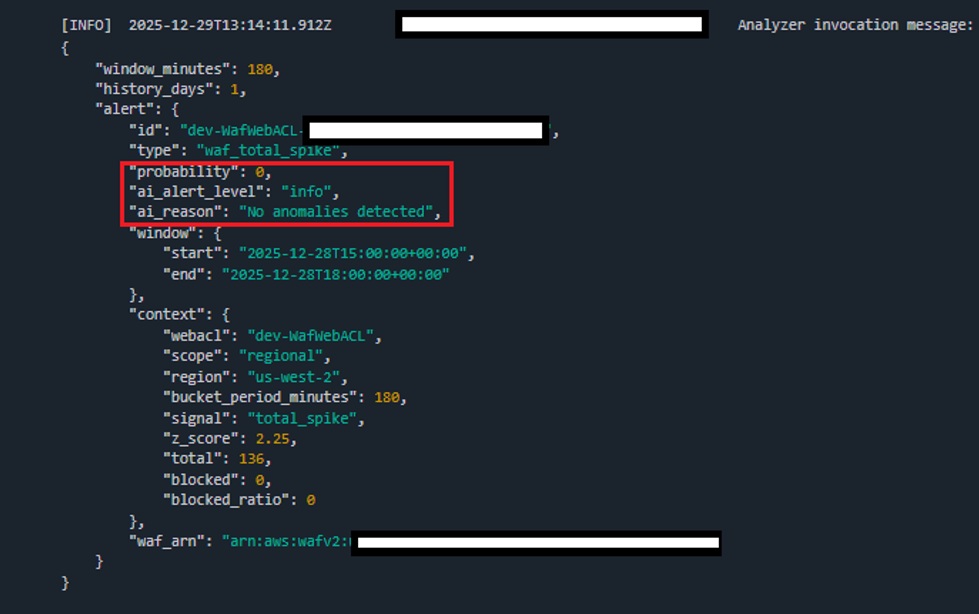
Test 2: Attack! 🚨
For the second test, use the Traffic Spike feature to simulate a high‑volume burst of suspicious requests targeting admin endpoints (e.g., /admin)—for example, 100 requests. Below is an example of the expected result:
Result: Lambda-Investigator detected the spike and forwarded context to Lambda-Analyzer. The admin received an email summarizing:
- Executive Summary: Spike of blocked requests from
44.xx.xx.xxtargeting admin paths, blocked byAWSManagedRulesAdminProtectionRuleSet— likely attempted admin access. - Quick Triage: severity, confidence score, number of examined events, top offender, and CloudTrail changes.
- Traffic Metrics: examined records and average WAF block ratio.
- Top Offenders: IP addresses of potential malicious actors.
- Top Rules: WAF rules triggered around detection time.
- WebACL Details: name, scope, region, ARN, number of enabled rules.
- Recommended Actions: investigate the source of blocked requests from the top offender.
(Analysis time: 3.76s ⏱️)
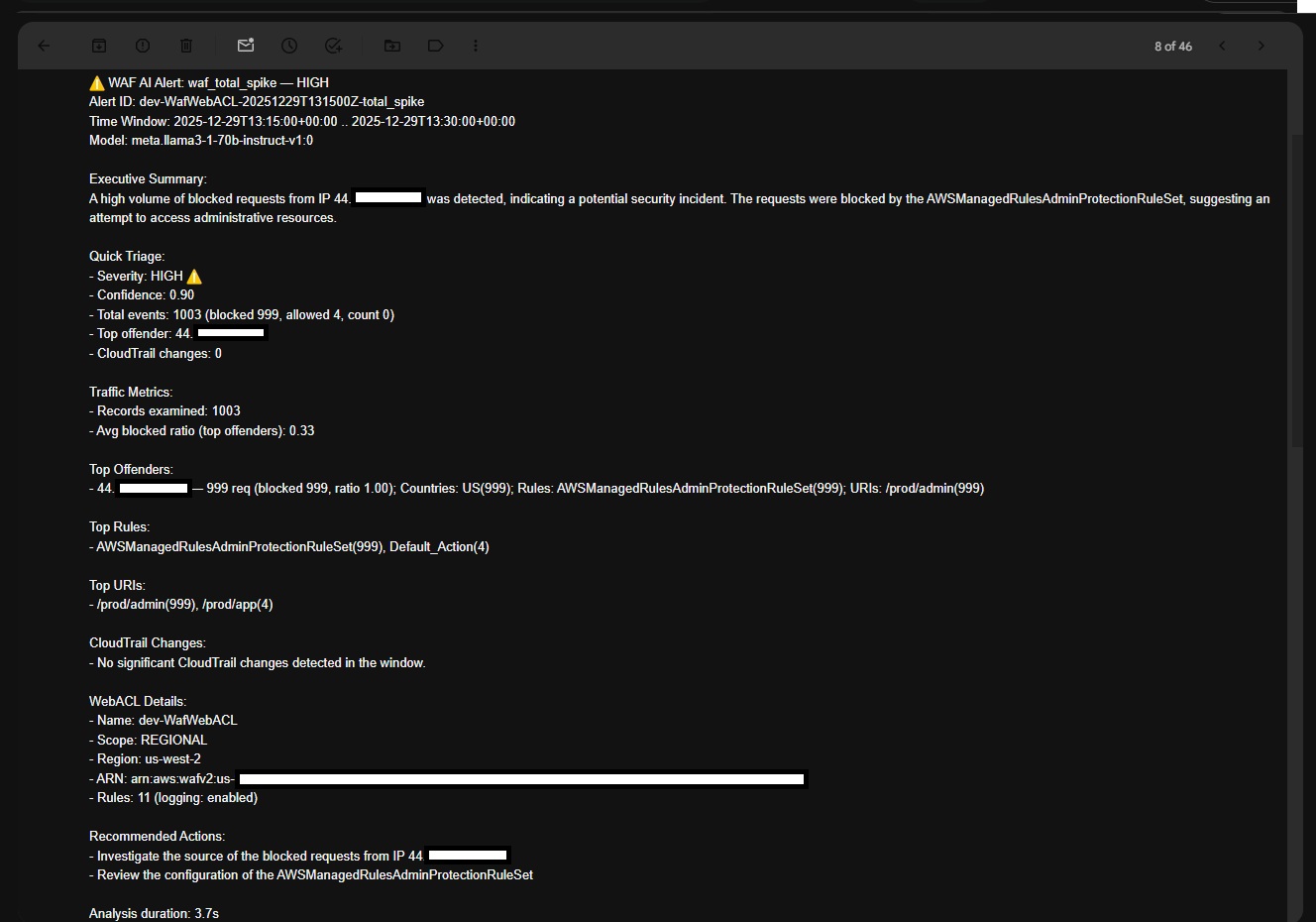
Test 3: Misconfiguration ⚙️
During the final test, first make an administrative change in AWS WAF—for example, create a custom rule to block all traffic from the US. Then, use the Traffic Spike function to generate a high volume of requests to a non-administrative path (e.g., 100 requests). Below is an example of the expected result:
Result: Lambda-Investigator detected the spike and forwarded it to Lambda-Analyzer. The admin received an email summarizing:
- Executive Summary: Spike to
/prod/app: 127 blocks from three IPs (54.xx.xx.xx,34.xx.xx.217,44.xx.xx.xx), all blocked byblock-rule-test-waf(US traffic). Recent WebACL changes bybartoszj@xxxx.commay have contributed. - Quick Triage: severity, confidence score, number of examined events, top offender, and CloudTrail changes.
- Traffic Metrics: examined records and average WAF block ratio.
- Top Offenders: IP addresses with the highest block counts.
- Top Rules: WAF rules triggered around detection time.
- Top URIs: URIs targeted around detection time.
- CloudTrail Changes: relevant events around detection time.
- WebACL Details: scope, region, ARN, number of enabled rules.
- Recommended Actions: review recent WebACL updates and verify whether blocking US traffic is necessary.
(Analysis time: 6.16s ⏱️)
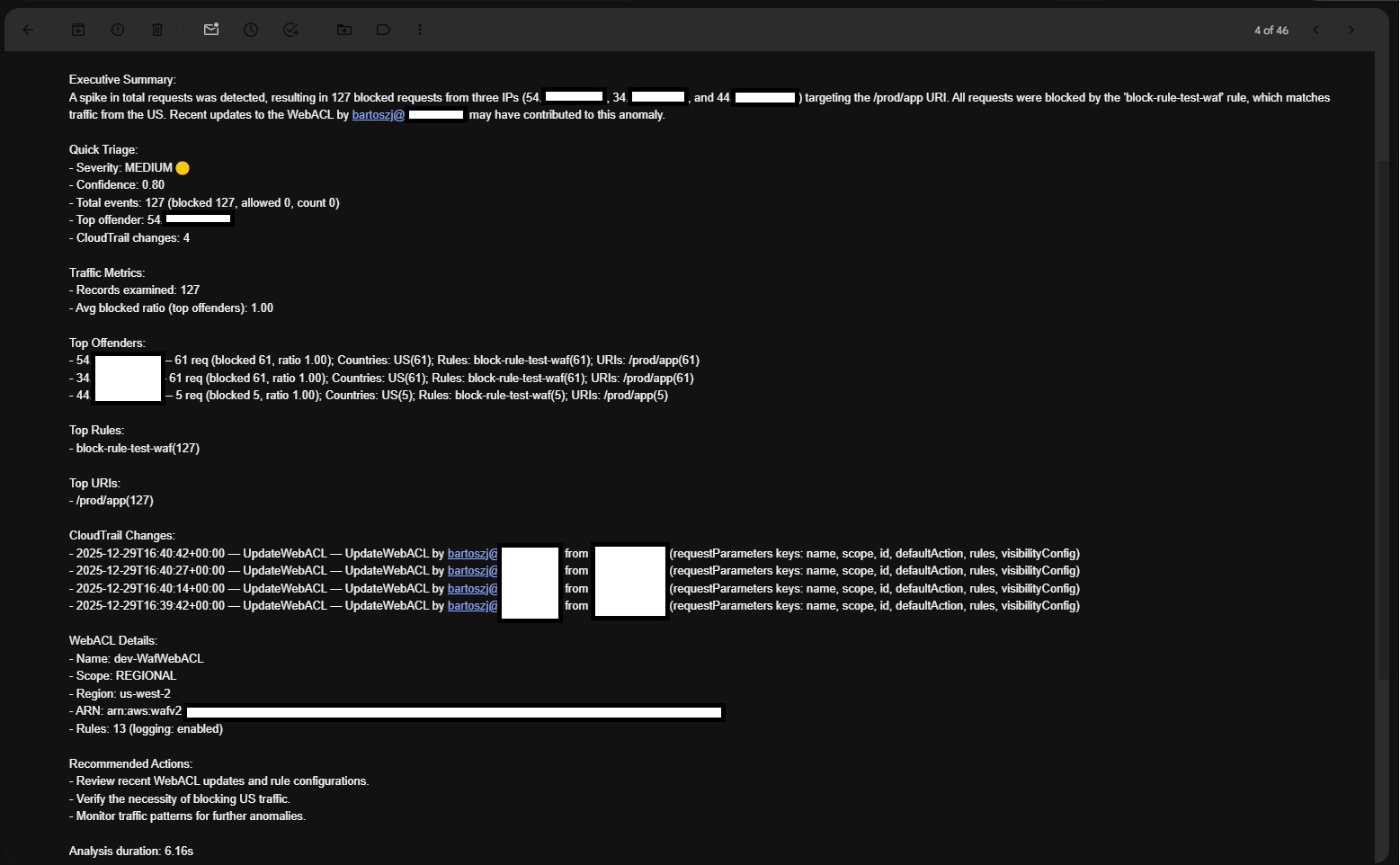
Results, Insights, and Next Steps
We built a simple, end-to-end system: AWS WAF + metrics/logs → Lambda + Amazon Bedrock → email alerts to demonstrate a practical AI use case for security.
While building this system, we validated three scenarios—regular traffic, attack, and misconfiguration—and the system behaved as expected: no alerts for normal baselines, targeted analysis and email summaries for spikes, and clear attribution for configuration changes.
In tests, Bedrock helped spot anomalies, explain likely causes, and significantly reduce investigation time—strengthening cloud security and operational awareness.
This is a proof of concept, not production; it’s meant to inspire and spark creativity. With AI, the possibilities are endless: auto‑triage, guided remediation, policy‑aware playbooks, and lightweight dashboards—these are just a few examples. Don’t stop here—keep exploring and building. When things don’t work at first, troubleshoot and iterate; that’s where the learning happens. We are all early in this AI journey. The most important outcome is the skills and knowledge gained along the way: designing prompts, wiring services, and validating signals.
Next steps: harden IAM, add Step Functions for robust orchestration, expand signals (e.g., AWS Shield, Amazon GuardDuty), apply S3 lifecycle policies for cost control, and keep refining prompts/models based on real telemetry.
And most importantly: stay curious, stay creative, and stay tuned for more deep dives and enhancements.